Avant d'en venir au dispositif qui donne son titre à cet article il me semble important de donner un peu de contexte. Je cherche depuis plusieurs mois maintenant à me procurer un bon et beau clavier mécanique. "Beau" est bien évidemment un critère totalement subjectif, et si "bon" inclue des éléments objectifs comme la solidité, la fiabilité, il intègre lui-aussi des éléments totalement subjectifs.
Ce qu'il y a de merveilleux dans le monde des claviers mécaniques haut de gamme, c'est qu'il est presque possible de faire n'importe quoi : si aucune marque ne propose un clavier tout fait qui vous corresponde, il est presque toujours possible d'en construire un qui répondent à nombre de vos critères. Presque, parce que la France n'est pas tout à fait cœur de cible : trop peu de demande pour susciter une offre variée, me suis-je laissé dire. Aussi le critère "AZERTY" ou ISO-FR est sans doute un des plus difficiles à remplir. Vous trouverez tous les claviers ou jeux de touches en ANSI-US, une portion raisonnable en ISO-UK, ISO-NO, ISO-DE, mais presque aucuns en ISO-FR. Ceux que vous trouverez seront les plus grand public, souvent des claviers de gamer dans des formats réduits comme le populaire TKL ("ten key less"), qui comme son nom l'indique fait l'impasse sur pas mal de touches.
 Après quelques mois d'étude du marché, de documentation sur les technologies, sur les capacités des claviers, sur les marques et leur réputation, de recherche d'un modèle qui réponde à mes besoins et à mes envies (surtout), j'ai fini par jeter mon dévolu sur deux modèles : le ViBE de Vortex Gear (photo ci-dessus), et le Tab 90M aussi chez Vortex Gear.
Après quelques mois d'étude du marché, de documentation sur les technologies, sur les capacités des claviers, sur les marques et leur réputation, de recherche d'un modèle qui réponde à mes besoins et à mes envies (surtout), j'ai fini par jeter mon dévolu sur deux modèles : le ViBE de Vortex Gear (photo ci-dessus), et le Tab 90M aussi chez Vortex Gear.
Bien sûr, je les veux en ISO-FR : je tape autant de texte que je code ou que je joue. J'ai besoin que mes accents et cédille soient accessibles sans contorsion. Et très honnêtement si je devais changer de disposition de touches j'irais sur un BEPO, pas sur l'archaïque ANSI-US.
J'ai plein d'autres critères que je ne détaille pas ici car ils n'ont aucun lien avec cette histoire de keylogger.
Comme on le remarque rapidement, le Vortex ViBE ne dispose pas de toutes les touches habituelles d'un clavier étendu : exit les flèches, page-down, page-up, etc. Toutes les touches entre le pavé numérique et le bloc de touches principal ont disparu. Par un jeu de combinaison de touches, il est possible d'utiliser le pavé numérique pour jouer le rôle des touches absentes. Dans mon quotidien, je fais un grand usage des flèches de navigation et du pavé numérique. En tout cas c'est ce qu'il me semble. J'utilise aussi les touches de fonctions (absentes sur le ViBE), et les touches "multimédia" du clavier étendu Apple qui est branché sur mes machines au travail et à la maison.
Je tenais donc à évaluer précisément l'usage que je fais de ces touches, histoire de ne pas prendre une trop grosse claque quand le fameux clavier arriverait. Et quoi de mieux pour savoir ce qu'on l'on tape toute la journée qu'un keylogger ? (réponse : rien).
La solution gratuite est assez facile à mettre en œuvre : trouver et installer sur mon poste un keylogger logiciel qui écrit dans un fichier texte tout ce qui passe par mon clavier. Mais cette solution est problématique à plusieurs égards. Notamment j'ai plusieurs machines. À la maison j'ai un OSX, un Windows et un FreeBSD, utilisés via un unique clavier physique au travers d'un switch USB. Il faudrait que je trouve une solution logicielle homogène à installer sur les trois systèmes. Au boulot et bien, juste non. Installer un keylogger logiciel qui pourrait exfiltrer à mon insu mes frappes clavier n'est réellement pas une bonne idée. Par ailleurs une solution logicielle attraperait aussi au vol ce qui sort de mes Yubikeys, et ça non plus ça ne me convient pas.
 La solution matérielle qui stocke mes frappes clavier en son sein, sans rien faire sortir et qui s'affranchit totalement du système sur lequel est branché le clavier me semble donc la plus sûre à tout point de vue, et la plus adaptée à mes besoins. Bien évidement je me suis assuré que le dongle n'exfiltre aucune données via mes machines. L'exfiltration de données via un réseau hertzien est assez peu probable même si le dispositif semble assez grand pour héberger une SIM et l'électronique nécessaire pour tout renvoyer par SMS. Par ailleurs comme le dongle est branché sur un unique clavier, il m'est toujours possible de saisir des données sensibles via un autre clavier :)
La solution matérielle qui stocke mes frappes clavier en son sein, sans rien faire sortir et qui s'affranchit totalement du système sur lequel est branché le clavier me semble donc la plus sûre à tout point de vue, et la plus adaptée à mes besoins. Bien évidement je me suis assuré que le dongle n'exfiltre aucune données via mes machines. L'exfiltration de données via un réseau hertzien est assez peu probable même si le dispositif semble assez grand pour héberger une SIM et l'électronique nécessaire pour tout renvoyer par SMS. Par ailleurs comme le dongle est branché sur un unique clavier, il m'est toujours possible de saisir des données sensibles via un autre clavier :)
Ceci posé, n'installez pas de keylogger chez vous sans savoir très exactement ce que vous faites et dans quoi vous mettez le doigt.
J'utilise le keylogger matériel depuis quelques dizaines de minutes, mais je vois déjà qu'il me faudra peut être tenter de le régler un peu finement : je tape trop vite pour lui, et pas mal de mots sont tronqués dans la capture. Cela a peut être aussi à voir avec le fait que c'est un modèle spécial supposé filtrer le trafic USB d'un clavier Apple. Les claviers Apple sont des hub USB, et sur le mien j'ai branché un casque/micro USB qui peut donc générer pas mal d'interférences au niveau du dongle qui connecte le clavier au switch USB. Quoi qu'il en soit ce n'est pas un drame puisque ce que je cherche à obtenir c'est une vue statistique de mes frappes, de mon utilisation du clavier.
Petit exemple de ce que cela donne :
[Sh]Parailleur comme le donge est branc sur un uniqu cver, il n[Bck]mest [Bck][Bck][Bck][Bck]e'est
Certains mots sont sévèrement amputés, mais l'esprit est là ! J'espère pouvoir obtenir des statistiques représentatives assez rapidement.
Bref, j'ai acheté un keylogger.
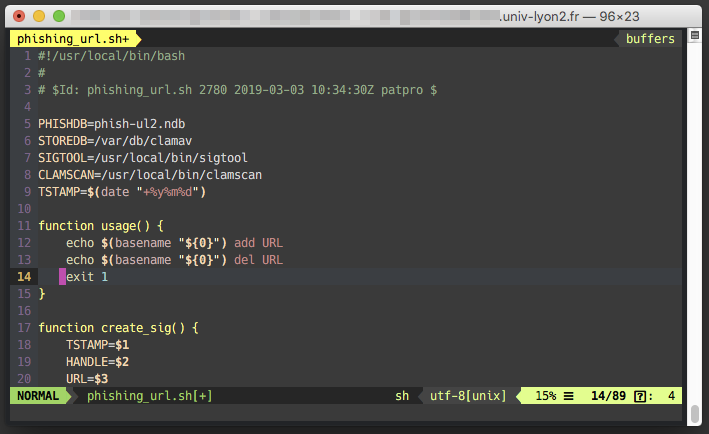
 Malheureusement pour cette forme d’écriture, les supports numériques prévalent de plus en plus, et la maîtrise du support disparaît presque totalement au profit d’intermédiaires, de médias, qui peuvent décider d’améliorer l’expérience utilisateur sans demander son avis à l’auteur initial. Que cet intermédiaire soit un logiciel bureautique, un CMS, une plateforme de réseau social, une application de SMS, une messagerie instantanée, etc. nombreux sont ceux qui vont s’arroger le droit d’activer les URL qu’ils détectent dans les contenus soumis. Ainsi, quand un auteur écrit que « les étudiant.es peuvent se porter candidat.es au concours d’infirmier.es », il est bien possible que le média de publication informe les lecteurs que « les
Malheureusement pour cette forme d’écriture, les supports numériques prévalent de plus en plus, et la maîtrise du support disparaît presque totalement au profit d’intermédiaires, de médias, qui peuvent décider d’améliorer l’expérience utilisateur sans demander son avis à l’auteur initial. Que cet intermédiaire soit un logiciel bureautique, un CMS, une plateforme de réseau social, une application de SMS, une messagerie instantanée, etc. nombreux sont ceux qui vont s’arroger le droit d’activer les URL qu’ils détectent dans les contenus soumis. Ainsi, quand un auteur écrit que « les étudiant.es peuvent se porter candidat.es au concours d’infirmier.es », il est bien possible que le média de publication informe les lecteurs que « les