BÉPO ?
Une fois de plus je vais parler clavier. Si vous atterrissez ici c'est sans aucun doute que vous en manipulez un de temps en temps. Il est probable que vous utilisez un clavier "AZERTY". Il existe plusieurs dispositions "AZERTY" différentes (française et belge, notamment). Pour bien faire la distinction il est donc préférable de faire référence au format ISO-FR pour un clavier normal français : lettres dans l'ordre azertyuiop, touche entrée en L inversé, etc. Les dispositions de référence sont listées et expliquées ici.
Bref, votre clavier est probablement dans une disposition commerciale très classique et répandue. Pour la plupart, ces dispositions sont aussi assez anciennes (fin 19ème siècle pour l'AZERTY). Elles ne sont pas toujours très adaptées à la langue pour laquelle elles ont été conçues. Depuis longtemps, des dispositions alternatives existent, avec pour ambitions de simplifier ou accélérer la saisie, de diminuer la fatigue des mains, etc. On peut citer par exemple la disposition Dvorak (1930), le "nouvel AZERTY" publié dans la norme AFNOR NF Z71-300 en 2019, ou encore le BÉPO dont une variante est intégrée à la même norme AFNOR et dont il va être question ici.
En attendant de voir si le nouvel AZERTY parvient à percer un jour, l'alternative BÉPO offre une belle ergonomie et a le mérite d'être presque trouvable dans le commerce pour qui sait chercher. Par ailleurs la couche logicielle existe pour la majorité des systèmes d'exploitations (Windows, macOS, Linux et BSD*).

Menu de choix de la disposition du clavier sous macOS après installation de la disposition BÉPO
Passant des journées entières devant mon clavier tout en n'ayant pas nécessairement une vitesse de frappe astronomique, il m'a semblé intéressant de tester la disposition BÉPO en vrai dans mon quotidien. Cela passera bien évidemment par une phase d'apprentissage et d'entraînement assez longue (les gens parlent de plusieurs mois avec un entraînement quotidien).
Le clavier
J'aurai pu apprendre à moindre frais sur mon clavier actuel : c'est en effet la partie logicielle installée sur l'ordinateur qui converti le signal envoyé par le clavier en lettre à l'écran, la légende de la touche en plastic n'a aucune importance. Donc en activant la disposition BÉPO sur mon système je peux apprendre à taper en BÉPO à condition de ne pas me fier aux légendes imprimées sur les touches. Je voulais plus que ça, j'ai donc investi dans un clavier que je vais dédier à cet usage, l'occasion aussi pour moi de tester un autre format de clavier (75%) et des interrupteurs (switches) tactiles, là où mes claviers actuels ont des switches linéaires. Bref, une expérience à 360° comme disent les gens 2.0.

switches sous les touches d'un clavier. © Keychron
Le kit de touches (les bidules en plastic qui sont fixés sur les switches et sur lesquels on appuie pour taper du texte), est issu d'un "group buy", une procédure de fabrication par achat groupé. Il s'agit de la variante Bépoléon du KAT Napoleonic.

Enseignements en vrac
La vie serait trop simple si elle n'avait pas son lot d'imprévus et de surprises et avant même d'avoir tapé mon premier email sur ce nouveau clavier j'ai essuyé quelques plâtres (dont un seul est lié à BÉPO) !
Silence relatif
Habitué aux switches linéaires "MX silent red" d'usine j'avais une certaine idée de ce que peut être le silence d'un clavier mécanique non personnalisé (quelque chose d'extrêmement relatif). Mais à force de lire sur les forums spécialisés que les MX sont dépassés, qu'il existe des switches bien meilleurs, plus innovants, plus silencieux, etc. On finit par y croire. C'est ainsi que je me suis penché sur la question : comment trouver des switches tactiles ET très silencieux qui ne coûtent pas un bras ? J'ai choisi les Gazzew Boba U4 qui ont fort bonne réputation. Je dois avouer que j'étais loin d'imaginer le résultat : finalement, en terme de silence ces switches semblent faire à peine mieux sur le Keychron que les MX silent red sur mes Vortex Tab90M. Par contre (et là aussi c'est une découverte pour moi), le Keychron avec les Gazzew Boba U4 est incroyablement plus silencieux que le Keychron avec les switches d'origine. Et pris sous cet angle, je comprends mieux que les Gazzew reçoivent autant de louanges.
Remplacement des switches
Le démontage des switches quant à lui a été assez douloureux. Une moitié environ a pu être extraite rapidement et sans effort avec l'outil fourni. L'autre moitié par contre a été très pénible à extraire, m'occasionnant de vives douleurs dans les extrémités des doigts à cause de l'ergonomie très frustre de l'extracteur métallique.
Interférences radio
Le K2 Pro peut fonctionner en filaire (USB-C) ou en Bluetooth. Après une charge partielle de la batterie j'ai testé la connexion Bluetooth du clavier. L'appairage se fait très simplement et rapidement sur macOS mais presque immédiatement j'ai entendu dans mes enceintes un vrombissement électronique caractéristique d'une interférence radio. Après différents tests j'ai pu déterminer que c'est la proximité de mon Mac Mini avec une de mes enceintes qui cause cette interférence désagréable quand le clavier est connecté en Bluetooth. Heureusement ce n'est pas le clavier.
Disposition et modification des touches
La connexion du clavier au logiciel VIA (en ligne dans un navigateur) n'est pas évidente pour le K2 Pro, il faut ruser un peu mais tout est expliqué sur le site de Keychron. Une fois qu'on a fait les bonnes manipulations c'est un jeu d'enfant de bricoler l'affectation des touches, de créer des macros, de personnaliser le rétroéclairage (je l'ai éteint), etc. Je ne pensais pas avoir besoin de personnaliser immédiatement la configuration du clavier, mais j'ai découvert en installant les touches KAT Napoléonic que Keychron a pris l'initiative déplorable de ne pas mettre les touches home/page up/page down/end dans l'ordre canonique dans la colonne tout à droite du clavier. Ils ont choisi l'ordre page up/page down/home/end si bien que sur un kit de touches alternatif comme le KAT Napoleonic, je n'avais pas les bonnes touches au bon endroit (les touches ont un profil qui dépend de leur emplacement sur le clavier, une touche qui n'est pas placée sur la bonne ligne n'aura pas la même forme que ses voisines). En réaffectant la touche home là où Keychron avait placé page up, page up à la place de page down et page down là ou se trouvait home, l'ordre était rétabli et j'ai pu placer les bonnes touches aux bons emplacements dans le respect de leur profil respectif.
Impact de BÉPO sur les Yubikeys et autres périphériques de type clavier
Jouer avec la disposition de clavier dans le système de son ordinateur peut occasionner quelques surprises. Une chose qui m'avait totalement échappé c'est la question des clés d'authentification comme les Yubikeys. J'en utilise de nombreuses, aussi bien à titre personnel que professionnel, en majorité pour du mot de passe statique (la clé tape à ma place un mot de passe fixe qui est enregistré dedans) et comme second facteur d'authentification avec l'OTP Yubico (la clé tape un mot de passe différent à chaque fois, vérifiable grâce à des éléments cryptographiques). Dans les deux cas, la clé se comporte exactement comme un clavier : elle envoie au système un code pour chaque caractère que l'on peut schématiser par l'exemple "2ème touche de la 3ème ligne". Cet exemple sur un clavier américain donnerait le caractère q, sur un clavier français le caractère a et sur un clavier BÉPO le caractère b. Yubico a bien fait les choses, et dans la majorité des cas, avec les réglages normaux, la clé envoie des suites de codes qui ont la particularité de correspondre au même caractère sur les claviers américains et européens standards. Ce n'est pas magique, ils ont simplement limité leur liste de caractères utilisables à la liste des caractères que ces différents claviers ont en commun (par exemple la lettre c qui est au même endroit partout). Ainsi, quand votre système est réglé pour un clavier anglais et que vous actionnez votre Yubikey pour entrer un OTP Yubico ou un mot de passe statique il y a toutes les chances pour que cela donne le même résultat que si vous réglez votre système pour un clavier français. Malheureusement la disposition BÉPO est tellement différente qu'elle n'a aucun caractère placé au même endroit que les autres dispositions, à part les chiffres. L'OTP Yubico ne peut donc nativement pas fonctionner sur un système réglé en BÉPO. Yubico indique qu'il est recommandé de basculer son système en disposition de clavier US avant de déclencher l'OTP ou le mot de passe statique puis de revenir à sa disposition habituelle. Cela fonctionne, bien sûr, mais peut être assez pénible. L'alternative est de forcer la configuration de la clé pour qu'elle convertisse ce qu'elle envoie pour que les codes correspondent à une disposition spécifique. Cela fonctionne avec BÉPO mais impose une limitation importante : la clé ne fonctionnera plus correctement si le système est réglé dans une autre disposition de clavier, donc l'utilisation de la même clé sur un ordinateur ou un smartphone qui n'est pas le mien ne serait plus possible à moins que la disposition BÉPO ne soit disponible et active sur l'appareil.
 La pandémie de COVID-19 a mis en lumière de nombreux éléments de notre quotidien auxquels nous n'étions pas habitués à prêter attention : l'impact des différents gestes "barrière" sur la transmission, mais aussi le traitement que l'on applique (ou pas) à notre air intérieur.
La pandémie de COVID-19 a mis en lumière de nombreux éléments de notre quotidien auxquels nous n'étions pas habitués à prêter attention : l'impact des différents gestes "barrière" sur la transmission, mais aussi le traitement que l'on applique (ou pas) à notre air intérieur. L'ergonomie se mesure à l'aune des usages de chacun. J'attache pour ma part une grande importance à la qualité des interactions avec les appareils et je n'aime pas la friction dans l'usage quotidien. Pour moi, c'est à nouveau l'Aranet4 qui remporte la palme avec son écran e-ink qui reste lisible tout le temps sans drainer les piles. Une fois paramétré via une application smartphone assez bien faite, plus besoin d'y revenir. C'est agréable.
L'ergonomie se mesure à l'aune des usages de chacun. J'attache pour ma part une grande importance à la qualité des interactions avec les appareils et je n'aime pas la friction dans l'usage quotidien. Pour moi, c'est à nouveau l'Aranet4 qui remporte la palme avec son écran e-ink qui reste lisible tout le temps sans drainer les piles. Une fois paramétré via une application smartphone assez bien faite, plus besoin d'y revenir. C'est agréable.










 Le passage de l'un à l'autre n'est donc pas immédiatement naturel, a fortiori quand on abuse comme moi des raccourcis clavier. La touche maîtresse sur Mac est ⌘, qui est "mappée" sur la touche Win dont la position est inversée avec la touche Alt entre les deux types de clavier. Je me retrouve donc assez régulièrement à tenter des raccourcis clavier "alt-truc" en voulant taper ⌘-truc alors qu'il faudrait que je tape Win-truc (qui sur un clavier Mac donnerait "alt-truc"). C'est très frustrant sur macOS où je passe le plus clair de mon temps, mais pas sur d'autres OS où la touche utilisée pour les raccourcis est ctrl.
Le passage de l'un à l'autre n'est donc pas immédiatement naturel, a fortiori quand on abuse comme moi des raccourcis clavier. La touche maîtresse sur Mac est ⌘, qui est "mappée" sur la touche Win dont la position est inversée avec la touche Alt entre les deux types de clavier. Je me retrouve donc assez régulièrement à tenter des raccourcis clavier "alt-truc" en voulant taper ⌘-truc alors qu'il faudrait que je tape Win-truc (qui sur un clavier Mac donnerait "alt-truc"). C'est très frustrant sur macOS où je passe le plus clair de mon temps, mais pas sur d'autres OS où la touche utilisée pour les raccourcis est ctrl. Autre aspect un peu pénible : sur un clavier Apple, la touche ⌘ est en deux exemplaires, de part et d'autre de la barre espace. Sur les claviers PC la touche Win n'existe qu'à gauche. Et ça s'est compliqué car la réalisation de certains raccourcis juste avec la main droite n'est plus possible tout en étant parfois trop tendue pour la main gauche, ce qui impose de faire Win avec la main gauche et la lettre ad-hoc avec la main droite. Les utilisateurs PC de longue date n'ont pas forcément ce souci, au moins ils en ont l'habitude et leurs doigts ne cherchent pas un raccourci que jamais ils ne trouvèrent. Dans le même ordre d'idée, l'emplacement du signe moins sur un clavier PC est une calamité incroyable, très hors d'atteinte alors qu'il (me) sert littéralement tout le temps. Sur clavier Apple il est à la place du signe égal à gauche de la touche Retour Arrière ce qui le rends très facile d'accès sans traverser tout le clavier.
Autre aspect un peu pénible : sur un clavier Apple, la touche ⌘ est en deux exemplaires, de part et d'autre de la barre espace. Sur les claviers PC la touche Win n'existe qu'à gauche. Et ça s'est compliqué car la réalisation de certains raccourcis juste avec la main droite n'est plus possible tout en étant parfois trop tendue pour la main gauche, ce qui impose de faire Win avec la main gauche et la lettre ad-hoc avec la main droite. Les utilisateurs PC de longue date n'ont pas forcément ce souci, au moins ils en ont l'habitude et leurs doigts ne cherchent pas un raccourci que jamais ils ne trouvèrent. Dans le même ordre d'idée, l'emplacement du signe moins sur un clavier PC est une calamité incroyable, très hors d'atteinte alors qu'il (me) sert littéralement tout le temps. Sur clavier Apple il est à la place du signe égal à gauche de la touche Retour Arrière ce qui le rends très facile d'accès sans traverser tout le clavier.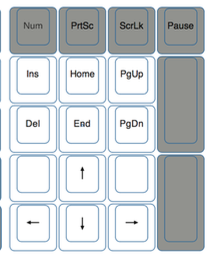 L'accès aux flèches et autres touches de navigation se fait sur le pavé numérique, immédiatement car par défaut le pavé n'est pas en verrouillage numérique. Cela se fait très naturellement et sans regarder tant leur disposition est proche de ce que l'on trouve sur des claviers étendus classiques. C'est très agréable car ça tombe naturellement sous les doigts.
L'accès aux flèches et autres touches de navigation se fait sur le pavé numérique, immédiatement car par défaut le pavé n'est pas en verrouillage numérique. Cela se fait très naturellement et sans regarder tant leur disposition est proche de ce que l'on trouve sur des claviers étendus classiques. C'est très agréable car ça tombe naturellement sous les doigts.
 La seule piste viable était donc de trouver une solution libre et ouverte, dans un langage que je comprenne a minima, de sorte que je puisse modifier le programme pour l'adapter à un clavier étendu en français.
La seule piste viable était donc de trouver une solution libre et ouverte, dans un langage que je comprenne a minima, de sorte que je puisse modifier le programme pour l'adapter à un clavier étendu en français.


