La signature des emails par clé DKIM est une composante importante d'un système de messagerie sain et bien géré. Comme tout système cryptographique fonctionnant sur la base d'un couple clé publique / clé privée, il est nécessaire de renouveler les jeux de clés régulièrement.
En effet, plus longtemps une même clé est utilisée, plus elle a de chance d'être cassée. De la même manière, plus elle est petite, plus elle sera facilement cassée.
Comme toujours, avec la correspondance par email, rien n'est instantané. Contrairement à un serveur web par exemple qui pourrait changer de certificat SSL en quelques minutes et faire immédiatement disparaître l'ancien de la circulation, les clés DKIM doivent changer selon un roulement tuilé : quand la nouvelle clé remplace l'ancienne, cette dernière doit rester disponible encore quelques temps pour permettre la validation des signatures présentes dans des messages encore en cours de livraison.
Ainsi, le besoin de faire tourner régulièrement les clés DKIM tout en garantissant un tuilage, ajouté à la complexité (relative) d'une architecture mixte à base de serveur DNS, serveur de mail, logiciel de signature DKIM, rendent nécessaire la mise en place d'une procédure claire, fiable et automatique.
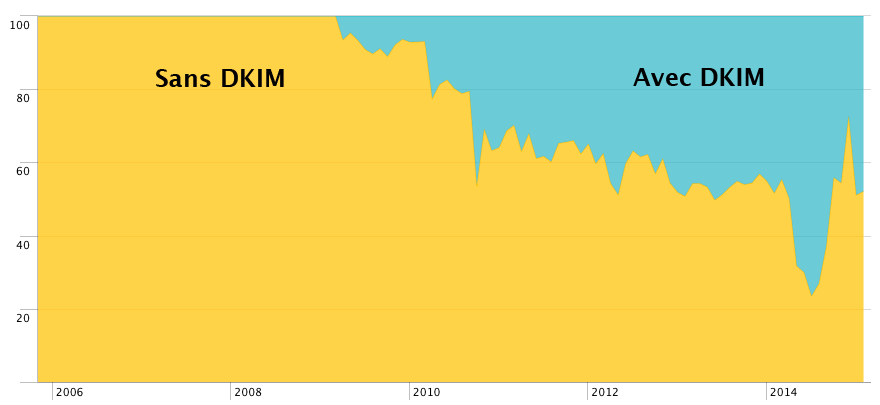
Évolution de l'utilisation de DKIM mesurée au niveau de l'antispam en entrée de mon serveur de mails, entre fin 2005 et début 2015
Pour mes propres besoins, j'ai conçu un script shell utilisable pour faire tourner les clés d'un domaine donné. Ce script s'appuie sur un serveur Bind local : la modification des zones DNS se fait par modification directe des fichiers. Il utilise l'implémentation DKIM de OpenDKIM.
Il serait tout à fait possible de concevoir un script qui utilise un serveur DNS distant ou local via la commande nsupdate(8), mais cette approche laisse la main totalement à Bind pour l'écriture des fichiers de zones. Il fait alors disparaître tous les commentaires, il change l'ordre des enregistrements, etc. Ce n'était pas souhaitable pour moi qui stocke des informations en commentaire dans mes fichiers de zones.
Prérequis pour utiliser ce script
- Être root sur le serveur ;
- Disposer d'un serveur DNS Bind, ou compatible (c'est OpenDKIM qui écrit les enregistrements DNS), maître pour les zones concernées par la rotation de clés ;
- Disposer sur la même machine d'une installation OpenDKIM fonctionnelle ;
- Avoir une version de sed qui supporte l'option -i (in place).
Comportement
Le premier argument obligatoire du script est l'action : renouvellement ("new") ou nettoyage ("clean"). Le second argument obligatoire est le domaine cible et le troisième argument (facultatif) est la longueur des nouvelles clés.
Pour l'action "new" et un domaine donné, le script renouvelle l'ensemble des clés DKIM. Par défaut, il génère des clés de la même longueur que celles qu'il remplace, et les sélecteurs sont nommés en `date "+%Y%m"` suivi d'un tiret et des 8 premiers caractères retournés par la commande uuidgen(1). Si une longueur de clé est imposée en argument, l'ensemble des clés du domaine utilisera cette nouvelle valeur. Pour l'action "clean" et un domaine donné, le script vidange les anciennes clés.
Pour assurer un tuilage d'une semaine par exemple, il faut donc le jour J lancer le script avec "new", et à J+7 lancer le script avec "clean" sur le même domaine. Ainsi, avant le jour J, la clé N est utilisée pour signer les messages. À partir du jour J, la clé N+1 est utilisée pour signer les messages, mais la clé N est encore disponible pour vérifier de vieux messages qui seraient encore en circulation. À partir de J+7, l'ancienne clé N disparaît.
Syntaxe des fichiers de zone DNS
Deux contraintes ici :
- Le numéro de série de la zone doit être seul sur sa ligne et suivi du commentaire " ; Serial" pour que le script puisse facilement le localiser et l'incrémenter.
- Les enregistrements DNS des clés DKIM doivent être en inclusion dans le fichier de la zone et résider respectivement dans le fichier dkim-active.${DOMAIN} pour les clés actives et dans le fichier dkim-retired.${DOMAIN} pour les clés inactives. Cela donne pour le fichier de zone patpro.net :
...
$INCLUDE "/etc/namedb/master/dkim-active.patpro.net"
$INCLUDE "/etc/namedb/master/dkim-retired.patpro.net"
...
Ainsi, le script peut très facilement déplacer les clés actives vers le fichier dkim-retired quand de nouvelles clés sont fabriquées et intégrées à dkim-active.
OpenDKIM
Les clés doivent être rangées par domaine, dans des répertoires qui portent le nom du domaine. Cela donne chez moi :
opendkim/patpro.net/201501-62e79011.private
opendkim/patpro.net/201501-62e79011.txt
opendkim/patpro.net/201501-82a3edc5.private
opendkim/patpro.net/201501-82a3edc5.txt
opendkim/proniewski.net/201502-e47af46c.private
opendkim/proniewski.net/201502-e47af46c.txt
Les clés utilisées doivent être référencées dans un fichier KeyTable unique que le script analyse pour retrouver les sélecteurs à remplacer, et réécrit avec les nouveaux sélecteurs.
Utilisation
crontab pour renouvellement automatique mensuel :
0 0 1 * * /usr/local/sbin/rotate-dkim.sh new patpro.net
0 0 8 * * /usr/local/sbin/rotate-dkim.sh clean patpro.net
ligne de commande pour changer la taille des clés d'un domaine :
rotate-dkim.sh new proniewski.net 2048
Corpus Scripti
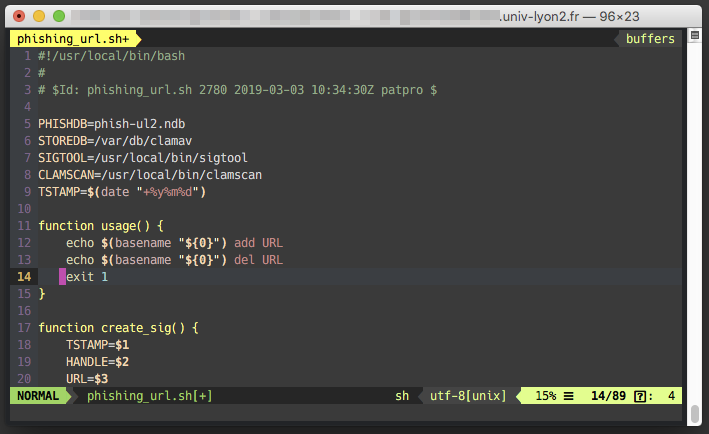
#!/usr/local/bin/bash
# rotate DKIM keys
PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin
# settings
ACTION=${1}
DOMAIN=${2}
NBITS=${3}; NBITS=$(( $NBITS+0 )) # force number
CHROOT=/var/db/opendkim
GENKEY=/usr/local/sbin/opendkim-genkey
KeyTable=/usr/local/etc/opendkim/KeyTable
ZONEROOT=/etc/namedb/master
USERGROUP=root:opendkim
ARCHIVE=/tmp/
MAXKEY=4096
MINKEY=512
onerror() {
case "$1" in
"args")
echo "usage: $(basename $0) new|clean domain.name [bits]"; exit 1
;;
"chroot")
echo "\$CHROOT must exist and be a directory"; exit 1
;;
"genkey")
echo "opendkim-genkey not found or not executable"; exit 1
;;
"ktable")
echo "KeyTable not found"; exit 1
;;
"zoneroot")
echo "\$ZONEROOT must exist and be a directory"; exit 1
;;
"usergroup")
echo "User and group must exist"; exit 1
;;
"archive")
echo "\$ARCHIVE must exist and be a directory"; exit 1
;;
"nbits")
echo "Bits length must be greater than $MINKEY, and should not be greater than $MAXKEY"; exit 1
;;
esac
}
# Checks
[ $# -ge 2 ] || onerror "args"
[ ${ACTION} = "new" -o ${ACTION} = "clean" ] || onerror "args"
[ -d ${CHROOT} ] || onerror "chroot"
[ -d ${ZONEROOT} ] || onerror "zoneroot"
[ -d ${ARCHIVE} ] || onerror "archive"
[ -x ${GENKEY} ] || onerror "genkey"
[ -f ${KeyTable} ] || onerror "ktable"
pw usershow ${USERGROUP/:*/} >/dev/null 2>&1 || onerror "usergroup"
pw groupshow ${USERGROUP/*:/} >/dev/null 2>&1 || onerror "usergroup"
if [ $NBITS -ne 0 ]; then
[ $NBITS -gt $MINKEY ] || onerror "nbits"
[ $NBITS -le $MAXKEY ] || onerror "nbits"
fi
archive() {
echo "Putting away files for old DKIM selector ${1}"
mv -v ${CHROOT}/${DOMAIN}/${1}.* ${ARCHIVE}
}
if [ ${ACTION} = "new" ]; then
# Keytable: update SELECTOR
# structure:
# arbitrary-name signing-domain:selector:keypath
# for each line matching DOMAIN:
# - get SELECTOR.
# - key path derived from CHROOT/SELECTOR
# get SELECTOR for DOMAIN:
SELECTORLIST=( $(awk '/^[^#].* '${DOMAIN}':/ {split($2,a,":"); print a[2]}' ${KeyTable}) )
# for each SELECTOR we must:
# - destroy/archive private key
# - create a new SELECTOR + key + DNS
# - rewrite KeyTable
echo ""
echo "Selector list for domain $DOMAIN has ${#SELECTORLIST[*]} member-s, lets renew each one:"
for OLDSELECTOR in ${SELECTORLIST[@]}; do
if [ $NBITS -ne 0 ]; then
echo "Bits length set on command line to ${NBITS}, overriding current private key bits length"
BITS=${NBITS}
else
echo -n "Get bits length for private key ${OLDSELECTOR}.private: "
BITS=$(openssl rsa -in ${CHROOT}/${DOMAIN}/${OLDSELECTOR}.private -text -noout | awk '/Private-Key/ {gsub(/[^0-9]/,"",$2); print $2}')
echo "$BITS"
fi
echo -n "Create new selector: "
UUID=$(uuidgen)
SELECTOR="$(date "+%Y%m")-${UUID/-*/}"
echo "${SELECTOR}"
echo "Create new private key with ${SELECTOR}:"
${GENKEY} -v -b ${BITS} -d ${DOMAIN} -D ${CHROOT}/${DOMAIN} -r -s ${SELECTOR}
# permission adjustments:
chown ${USERGROUP} ${CHROOT}/${DOMAIN}/${SELECTOR}.*
chmod u=r,g=r ${CHROOT}/${DOMAIN}/${SELECTOR}.*
ls -l ${CHROOT}/${DOMAIN}/${SELECTOR}.*
echo -n "Update KeyTable: "
sed -i .bkp -e 's/'$OLDSELECTOR'/'${SELECTOR}'/g' ${KeyTable}
[ $? -eq 0 ] && echo "OK"
archive ${OLDSELECTOR}
done
echo ""
echo "End of selector renewal."
# every SELECTOR for DOMAIN is updated, now deal with DNS
fi
echo ""
# calculate new serial for zone $DOMAIN
echo -n "Get old DNS zone serial for ${DOMAIN} and increment: "
NEWSERIAL=$(date +%Y%m%d%I)
OLDSERIAL=$(awk '/ ; Serial/ {print $1}' ${ZONEROOT}/${DOMAIN})
while [ $OLDSERIAL -ge $NEWSERIAL ]; do
let NEWSERIAL=(NEWSERIAL+1)
done
echo "$OLDSERIAL -> $NEWSERIAL"
#
# Update SERIAL of DNS zone.
echo -n "Change serial in zone file: "
sed -i .bkp -e 's/'$OLDSERIAL' ; Serial/'${NEWSERIAL}' ; Serial/g' ${ZONEROOT}/${DOMAIN}
[ $? -eq 0 ] && echo "OK"
if [ ${ACTION} = "new" ]; then
echo -n "Move old public keys to dkim-retired.${DOMAIN}: "
cat ${ZONEROOT}/dkim-active.${DOMAIN} > ${ZONEROOT}/dkim-retired.${DOMAIN}
[ $? -eq 0 ] && echo "OK"
echo -n "Copy new public keys to dkim-active.${DOMAIN}: "
cat ${CHROOT}/${DOMAIN}/*.txt > ${ZONEROOT}/dkim-active.${DOMAIN}
[ $? -eq 0 ] && echo "OK"
elif [ ${ACTION} = "clean" ]; then
echo -n "Clean old public keys of dkim-retired.${DOMAIN}: "
echo "" > ${ZONEROOT}/dkim-retired.${DOMAIN}
[ $? -eq 0 ] && echo "OK"
fi
echo ""
echo "Everything looks good, lets refresh world:"
named-checkzone ${DOMAIN} ${ZONEROOT}/${DOMAIN}
service named restart
[ ${ACTION} = "new" ] && service milter-opendkim restart
Les commentaires dans le code sont suffisants pour expliquer chaque étape du déroulement du script.
Bibliographie
DKIM
M3AAWG DKIM Key Rotation Best Common Practices (PDF)

 La création de nouveaux mots de passe est une activité assez peu passionnante, d'autant que dans certains contextes on peut être amené à répéter l'opération plusieurs fois par jour. Plutôt que d'avoir à réfléchir - et donc de produire un résultat influencé par les travers de l'esprit humain - il est préférable de s'en remettre totalement à la machine.
La création de nouveaux mots de passe est une activité assez peu passionnante, d'autant que dans certains contextes on peut être amené à répéter l'opération plusieurs fois par jour. Plutôt que d'avoir à réfléchir - et donc de produire un résultat influencé par les travers de l'esprit humain - il est préférable de s'en remettre totalement à la machine.
 Donner des conseils en matière de mot de passe, c'est délicat. Ça implique en général de croire un minimum dans le système de protection par mot de passe. Et comme toute la sécurité en général, le mot de passe est un compromis, et comme tout compromis, il est donc faillible. Je crois personnellement de moins en moins au principe du mot de passe pour protéger des informations vraiment vitales. Sans doute suis-je encouragé dans cette impression par des démonstrations récentes de casse de mots de passe complexes-mais-humainement-utilisables.
Donner des conseils en matière de mot de passe, c'est délicat. Ça implique en général de croire un minimum dans le système de protection par mot de passe. Et comme toute la sécurité en général, le mot de passe est un compromis, et comme tout compromis, il est donc faillible. Je crois personnellement de moins en moins au principe du mot de passe pour protéger des informations vraiment vitales. Sans doute suis-je encouragé dans cette impression par des démonstrations récentes de casse de mots de passe complexes-mais-humainement-utilisables.