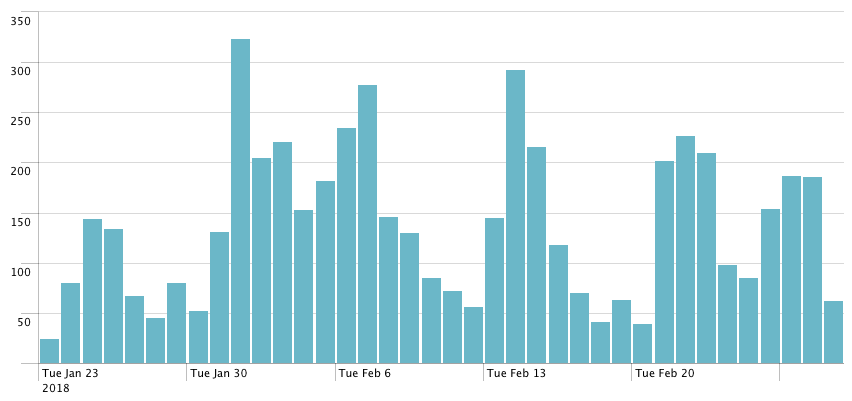
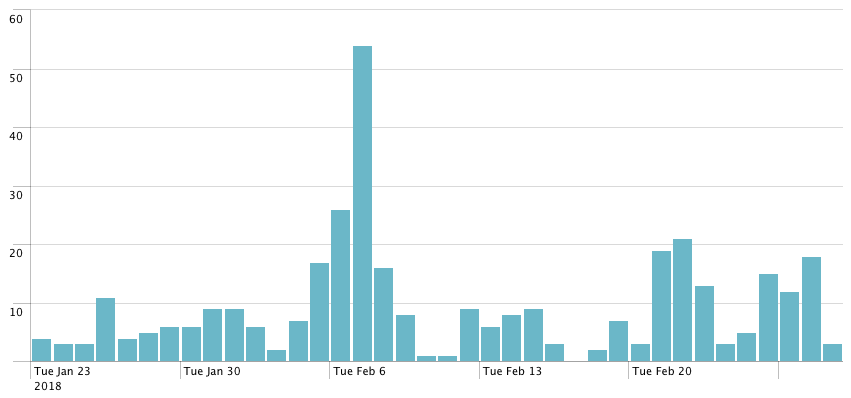
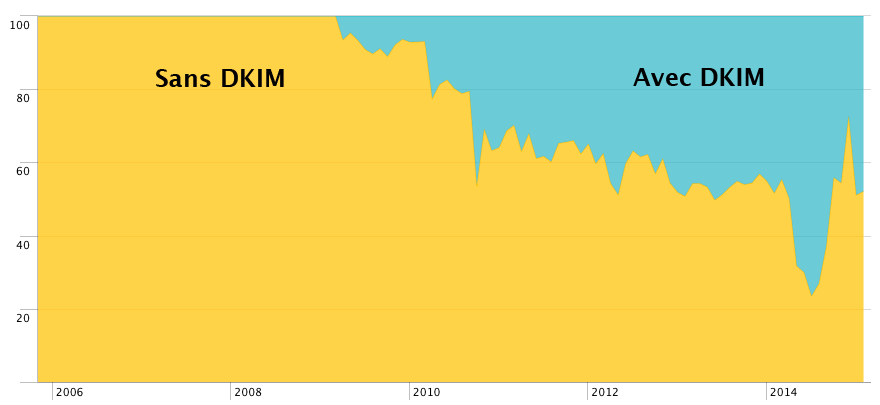
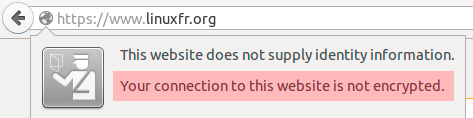
I am so pissed, right now, against the Internet. Its content is now so highly irrelevant and so motivated by easy profit (ads) that you can't find anything valuable when you try to solve a "common" tech problem.
I am so pissed, right now, against the Internet. Its content is now so highly irrelevant and so motivated by easy profit (ads) that you can't find anything valuable when you try to solve a "common" tech problem.
It's like you are back to the pre-Internet days but you will still lose your sanity and you precious time on Earth googling for help. Infuriating.
Yesterday evening, I thought it would be a good idea to play few minutes with Airplay between my iPad (on WIFI) and my new LG TV (on Ethernet). I've tried it before, it worked instantly and it was great. Few minutes became +1h45 of fight.
As a professional Sysadmin I've started to list what could have changed between my initial flawless experience and this huge failure: iPadOS updates (can't roll back for testing), LG TV updates (can't roll back either), Pi-hole installation (can disable very easily). Disabling Pi-hole filtering yielded to zero progress. Then I've started asking Google with queries like "LG TV airplay stopped working" and so many variations I've lost the count.
Every single results page served the same crap to me:
"LG TV AirPlay Not Working (PROVEN Fix!)"
"Airplay Not Working on LG TV | Fix in Easy Methods [2022]"
"AirPlay Not Working on LG TV: How to fix - Blue Cine Tech"
"13 Fixes For LG TV Airplay Not Working - TV To Talk About"
"AirPlay Not Working on LG TV (Do This FIRST!) in 2022"
etc.
13 fixes? SERIOUSLY? All these web pages are clickbait copy-pasta of the same semi-automatically generated content that contradicts itself (one fix: you must absolutely use WIFI, other fix: use Ethernet if WIFI does not work…) and conveys false informations.
Internet is failing hard on people.
After more tests and thinking I knew something was going on in the background that was probably not related to Airplay: starting the Airplay mirroring from the iPad made the TV displaying a black screen with a message about an incoming Airplay connection from name of my device and a 4 digits code that I had to type onto the device. Entering the code yielded only to the iPad complaining about Airplay connection failure.
So, to be clear about that particular tech issue of mine and about Airplay in general:
- Airplay works flawlessly on a mixed network (WIFI+Ethernet) as long as your devices are on the same network (192.168.0.0/24 for example).
- Your devices don't have to be on the same WIFI network. Every one who writes the opposite is either lying, taking a huge shortcut, or is being clueless about Airplay.
- I solved my problem by accepting "Viewing Information" item in the "User Agreements" panel of the TV. Those agreements are in blatant violation with the GDPR but I've neither time nor resources to start a legal fight with LG so I trick the TV with Pi-hole so whatever I consent to, they can't use or collect.
Full (unstable) trick:
- shutdown TV, remove power for 1 minute
- disable Pi-hole for 5 minutes
- re-plug TV, start TV
- go to settings>User Agreements
- check "Viewing Information", then hit the "Agree" button
- test Airplay: it works!
- ensure Pi-hole is active
- disable "Viewing Information" in the "User Agreements"
- TV says it must reboot to disable specific content you can access only if you agree blahblah…
- throw your best villain laugh as you watch the TV rebooting and coming back with a functional Airplay but no "Viewing Information" agreement.
Unfortunately this trick will no survive long (next morning Airplay was dead again). If I want a more simple and stable setup I must agree permanently to the "Viewing Information" item and follow this process:
- shutdown TV
- disable Pi-hole 30 or 60 sec.
- Start TV
- initiate Airplay from iPad
- For privacy's sake it's wise to reboot the TV when done with Airplay, to ensure full Pi-hole protection
I don't know what Apple would think of that totally artificial limitation LG has put in it's implementation of an Airplay client/target, but it looks fishy to me.
I probably should have titled this post "What they don't want you to know about Airplay on LG TV".
 Malheureusement pour cette forme d’écriture, les supports numériques prévalent de plus en plus, et la maîtrise du support disparaît presque totalement au profit d’intermédiaires, de médias, qui peuvent décider d’améliorer l’expérience utilisateur sans demander son avis à l’auteur initial. Que cet intermédiaire soit un logiciel bureautique, un CMS, une plateforme de réseau social, une application de SMS, une messagerie instantanée, etc. nombreux sont ceux qui vont s’arroger le droit d’activer les URL qu’ils détectent dans les contenus soumis. Ainsi, quand un auteur écrit que « les étudiant.es peuvent se porter candidat.es au concours d’infirmier.es », il est bien possible que le média de publication informe les lecteurs que « les
Malheureusement pour cette forme d’écriture, les supports numériques prévalent de plus en plus, et la maîtrise du support disparaît presque totalement au profit d’intermédiaires, de médias, qui peuvent décider d’améliorer l’expérience utilisateur sans demander son avis à l’auteur initial. Que cet intermédiaire soit un logiciel bureautique, un CMS, une plateforme de réseau social, une application de SMS, une messagerie instantanée, etc. nombreux sont ceux qui vont s’arroger le droit d’activer les URL qu’ils détectent dans les contenus soumis. Ainsi, quand un auteur écrit que « les étudiant.es peuvent se porter candidat.es au concours d’infirmier.es », il est bien possible que le média de publication informe les lecteurs que « les