Compte tenu des masses titanesques d'emails qu'un serveur peut être amené à traiter quotidiennement, l'optimisation des performances pour son logiciel de filtrage antispam est primordiale. C'est encore plus vrai si vous pratiquez le before queue content filtering.
Depuis plusieurs mois, vraisemblablement suite à une mise à jour d'une librairie ou d'un composant de l'antispam, j'ai constaté sur le SMTP authentifié @work un délai de traitement anormal dans certains cas. La durée normale pour le filtrage d'un message se situe entre 0 et 1 seconde, et pour une portion non-négligeable d'entre eux, cette durée passe à 30 secondes presque tout rond :
normal : anormal :
elapsed: { elapsed: {
Amavis: 0.059 Amavis: 0.267
Decoding: 0.019 Decoding: 0.026
Receiving: 0.002 Receiving: 0.002
Sending: 0.027 Sending: 0.229
SpamCheck: 0.156 SpamCheck: 30.113
Total: 0.224 Total: 30.398
VirusCheck: 0.003 VirusCheck: 0.008
} }
Une recherche en mode debug m'a rapidement orienté vers un souci avec le filtrage bayésien :
SA dbg: locker: safe_lock: created /.../bayes.lock.foobar.19635 SA dbg: locker: safe_lock: trying to get lock on /.../bayes with 0 retries SA dbg: locker: safe_lock: trying to get lock on /.../bayes with 1 retries SA dbg: locker: safe_lock: trying to get lock on /.../bayes with 2 retries SA dbg: locker: safe_lock: trying to get lock on /.../bayes with 3 retries SA dbg: locker: safe_lock: trying to get lock on /.../bayes with 4 retries SA dbg: locker: safe_lock: trying to get lock on /.../bayes with 5 retries SA dbg: locker: safe_lock: trying to get lock on /.../bayes with 6 retries SA dbg: locker: safe_lock: trying to get lock on /.../bayes with 7 retries SA dbg: locker: safe_lock: trying to get lock on /.../bayes with 8 retries SA dbg: locker: safe_lock: trying to get lock on /.../bayes with 9 retries
Ces 10 tentatives de prise de verrou ont souvent lieu 3 fois de suite, et chaque série dure 10 secondes : mon délai de 30 secondes est trouvé.
Le problème se trouvant du côté des fonctions d'accès à la base de données bayésienne, j'ai deux options : le résoudre ou le contourner. Le résoudre impliquerait probablement plusieurs journées d'analyse très fine et surtout de nombreux tests intrusifs sur une machine de production : pas envisageable.
J'ai donc pris le parti remplacer le stockage bayésien basique (Berkeley DB) par un stockage "haute performance" basé sur une base de données Redis.
Le changement est très simple à implémenter et totalement réversible. Le serveur Redis étant déjà installé sur la machine pour recueillir les logs détaillés d'Amavisd-new, il y a très peu de modifications à apporter pour y stocker les "seen" et les "token" de SpamAssassin.
Le support de Redis est inclus nativement dans Spamassassin depuis la version 3.4.0. Il suffit donc de placer les bons réglages et de recharger amavisd-new :
Dans le fichier /usr/local/etc/mail/spamassassin/local.cf on ajoute les lignes suivantes :
bayes_store_module Mail::SpamAssassin::BayesStore::Redis bayes_sql_dsn server=127.0.0.1:6379;password=foo;database=3 bayes_token_ttl 21d bayes_seen_ttl 8d
Et on recharge amavisd-new avec la commande sudo amavisd reload.
Il faut ensuite utiliser sa-learn pour faire apprendre à la nouvelle base vierge 200 messages de spam et 200 messages de ham, sans quoi la base bayésienne ne sera pas utilisée lors de l'analyse antispam.
Le gain de performance est immédiat : comme il s'agit d'une base de données NoSQL en mémoire, il n'y a pas de contrainte de verrou sur des fichiers, et la très forte concurrence des requêtes n'est plus un souci.
Entre la semaine 17 et la semaine 18 on constate la disparition quasi-totale des longs temps d'analyse, notamment dans la zone des 30 secondes (attention à l'échelle log) :
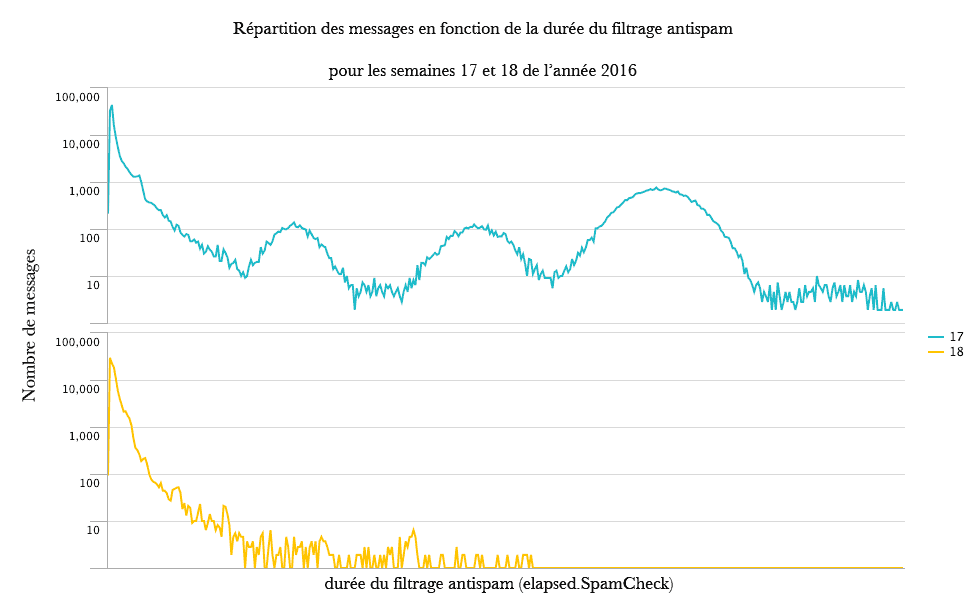
Les trois bosses se situent respectivement autour de 10, 20 et 30 secondes. On remarque aussi que les performances de cette semaine 18 (avec Redis) sont meilleures que celles d'une semaine précédant l'arrivée du problème (bosse à 10 secondes) :
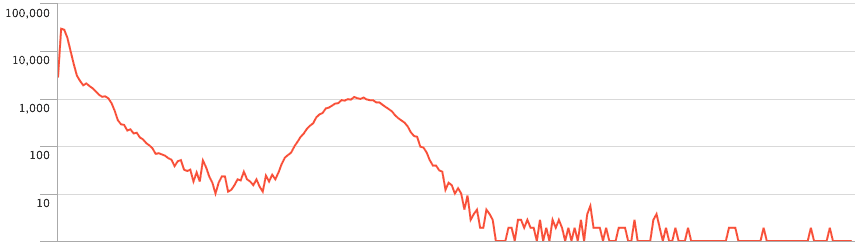
Une autre représentation des mêmes données montre de manière spectaculaire l'amélioration des temps d'analyse :
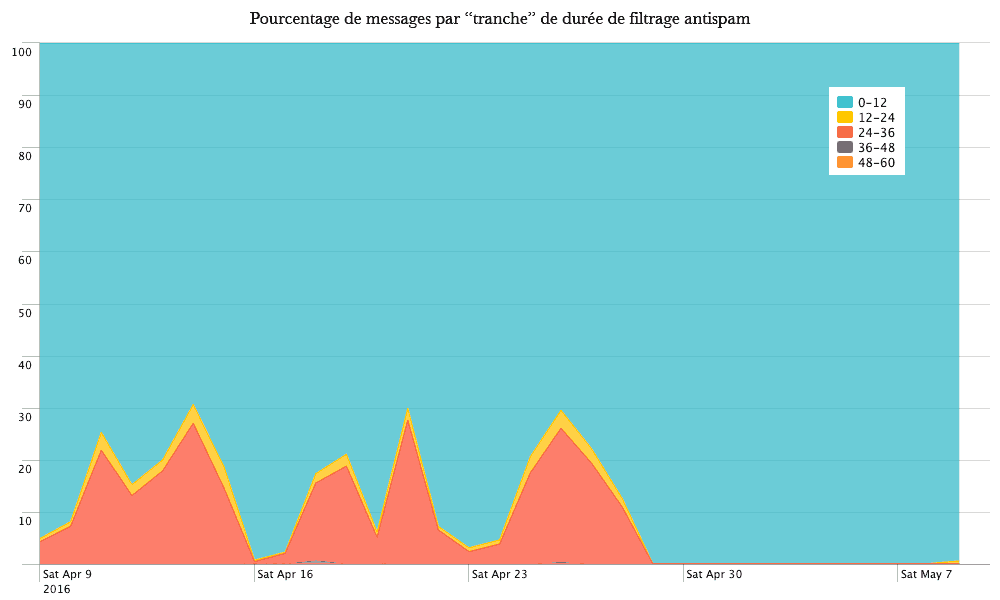
Cette modification relativement simple améliore clairement le ressenti des utilisateurs du serveur SMTP (ie. qui ne passent pas par une interface "webmail"). Leur client de messagerie ne les fera plus attendre 30 secondes par envoi lors des périodes de forte affluence, et le filtrage en Before Queue est préservé. Le meilleur des deux mondes !