Même si la question a déjà été largement traitée, je livre ici ma propre version d'un trou noir DNS. Le DNS blackhole, en anglais dans le texte, permet par exemple de s'assurer (dans une certaine mesure) que les utilisateurs de votre réseau ne peuvent pas se connecter trop facilement à des sites web vecteurs d'infection.
Le fonctionnement est simple : vous avez un réseau local, chez vous ou dans votre entreprise, et vous mettez à disposition de vos utilisateurs un serveur DHCP pour que les équipements qui se connectent puissent obtenir une adresse IP. Je pars du principe que sur ce réseau local, vous disposez aussi d'un serveur DNS. Un utilisateur se connecte avec votre réseau : le serveur DHCP lui donne une adresse IP pour que la nouvelle machine puisse parler sur le réseau, et fourni aussi l'adresse de votre serveur DNS. C'est donc par ce serveur que vous maitrisez que la machine de l'utilisateur va convertir les noms de domaine (www.patpro.net) en adresse IP (193.30.227.216).
Comme vous avez la maîtrise du serveur DNS, vous avez la maîtrise de la résolution des noms de domaine. Vous pouvez donc décider de bloquer la résolution de certains noms de sites web qui posent problème (gros pourvoyeurs de malware, régies publicitaires, facebook, etc.).
Je vais me baser ici sur la liste de malwaredomains.com qui regroupe environ 20000 noms de domaine qui sont, ou ont été, impliqués dans la distribution de malware (en général en infectant le visiteur imprudent). Il s'agit donc pour moi de défendre mon réseau en protégeant les utilisateurs.
Les informations sont largement inspirées - voire pompées - de la prose anglophone de Paul.
Pré-requis : un serveur DNS BIND que vous maîtrisez, et un réseau avec serveur DHCP qui indique l'adresse IP du DNS, de sorte que les clients qui se connectent utiliseront par défaut le serveur DNS sus-mentionné. Il faut bash, curl, et jot (sur linux il faut remplacer jot par seq).
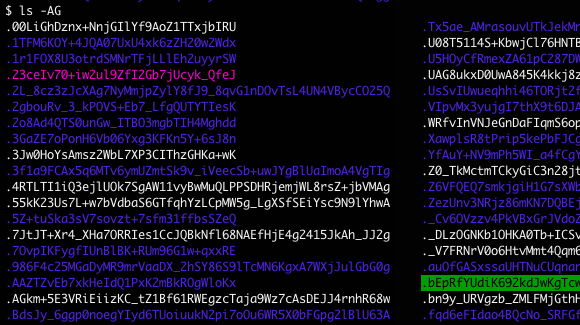
Obtenir la liste des zones DNS à mettre en trou noir.
Préparer le lieu de stockage :
mkdir /etc/namedb/blackhole
J'utilise le script suivant, à lancer en root via une crontab (une fois par semaine suffit) :
#!/usr/local/bin/bash
PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin
ZONEFILE=/etc/namedb/blackhole/spywaredomains.zones
MIRRORS[1]="http://mirror1.malwaredomains.com/files/spywaredomains.zones"
MIRRORS[2]="http://mirror2.malwaredomains.com/files/spywaredomains.zones"
MIRRORS[3]="http://dns-bh.sagadc.org/spywaredomains.zones"
# fonctionne sur BSD uniquement, pour linux il faut
# remplacer par `seq`
CHOOSE=$(jot -r 1 1 ${#MIRRORS[@]})
if [[ "$(/usr/local/bin/curl ${MIRRORS[CHOOSE]} -z ${ZONEFILE} -o ${ZONEFILE}_new -s -L -w %{http_code})" == "200" ]]; then
rm -f ${ZONEFILE}_old
mv ${ZONEFILE} ${ZONEFILE}_old
mv ${ZONEFILE}_new ${ZONEFILE}
named-checkconf -z | grep -v ": loaded serial"
if [ ${PIPESTATUS[0]} -eq 0 ]; then
service named restart
else
echo "Error loading new zone file, reversing..."
mv ${ZONEFILE} ${ZONEFILE}_invalid_$(date "+%Y%m%d")
mv ${ZONEFILE}_old ${ZONEFILE}
fi
fi
C'est loin d'être foolproof, mais ça fait le travail. Les options de curl permettent de ne télécharger le fichier que si il a été modifié depuis votre dernière mise à jour. le script choisit un miroir au hasard au moment de faire le comparatif ce qui évite de charger toujours le même serveur.
Configurer BIND pour gérer les zones téléchargées.
Il faut ajouter dans la configuration du serveur DNS une directive d'inclusion du fichier téléchargé ci-dessus. Il suffit pour cela d'ajouter la ligne suivante à la fin du fichier /etc/named/named.conf :
include "/etc/namedb/blackhole/spywaredomains.zones";
Le fichier spywaredomains.zones fait pointer chaque zone vers un unique fichier de définition qu'il convient de créer et de renseigner : /etc/namedb/blockeddomain.hosts.
Ce fichier contient une définition minimaliste de zone DNS BIND. Faites-la pointer vers un serveur web existant, cela vous permettra d'afficher à vos utilisateurs une page web d'explication :
$TTL 86400 ; one day @ IN SOA NOM-DE-VOTRE-SERV-DNS. NOM-DE-VOTRE-SERV-DNS. ( 1 28800 ; refresh 8 hours 7200 ; retry 2 hours 864000 ; expire 10 days 86400 ) ; min ttl 1 day NS NOM-DE-VOTRE-SERV-DNS. A IP-DE-VOTRE-SERVEUR-WEB * IN A IP-DE-VOTRE-SERVEUR-WEB
Si vous ne souhaitez pas informer vos utilisateurs, remplacez simplement IP-DE-VOTRE-SERVEUR-WEB par 127.0.0.1. Mais je recommande tout de même la publication d'une page web d'information sur la quelle les utilisateurs pourront arriver si ils tentent de joindre un domaine présent dans la liste noire.
Avec ça, votre serveur DNS est transformé en trou noir pour l'ensemble des domaines répertoriés chez malwaredomains.com. En analysant les logs de votre serveur web, vous pourrez aussi déterminer rapidement qui sur votre réseau est infecté ou risque de l'être.
Références.
- http://www.pintumbler.org/Code/dnsbl
- malwaredomains.com
- http://blog.yjl.im/2012/03/downloading-only-when-modified-using.html
edit : correction d'une coquille dans le script