Il existe des tas de bonnes raisons d'utiliser cron plutôt que launchd pour lancer des tâches périodiques sur un Mac OS X. La première étant l'écrasante complexité de launchd face à cron. Néanmoins, Apple fait presque tout pour nous décourager d'utiliser cron, donc il est peut être temps de jeter un œil à launchd. J'ai déjà montré comment ce dernier permet de créer des tunnels ssh à la demande pour la connexion d'applications. Voyons maintenant comment il peut aussi être utilisé, dans une certaine mesure, pour s'acquitter de tâches périodiques.
Vous êtes peut être arrivé sur cette page à cause d'un vilain message dans vos fichiers de log système :
...cron...Could not setup Mach task special port 9: (os/kern) no access
Si vous trouvez ce message dans votre fichier /var/log/system.log, c'est que vous utilisez, peut être à votre insu, des crontabs. Les crontabs sont des fichiers de configuration pour cron. Le système râle pour vous faire comprendre à demi-mot qu'il serait temps d'utiliser launchd, et de laisser cron à vos ancêtres.
Généralement, une crontab se présente sous cette forme (sortie de la commande crontab -l) :
# Collect system information every minute * * * * * /Users/patpro/bin/cpu_load.sh >/dev/null # Status graphs generation */15 * * * * /Users/patpro/bin/cpu_load_graphs.sh >/dev/null
J'ai donc ici un script lancé toutes les minutes, et un script lancé toutes les 15 minutes.
La première complexité de launchd c'est que nous allons avoir un fichier de configuration de plusieurs lignes pour chaque ligne de la configuration de cron. Chaque action gérée par launchd fait l'objet d'une déclaration dans un fichier XML. Pour les actions périodiques de type crontab, il faut que launchd les prennent en charge dès le démarrage de la machine. Il faut aussi que les scripts ou applications soient lancés indépendamment de l'utilisateur. Pour remplir ces conditions, il faut que les fichiers XML soient placés dans /Library/LaunchDaemons/.
Voici le fichier XML correspondant à la première ligne de ma crontab, il se nomme ma.crontab.cpu_load.plist et est enregistré dans /Library/LaunchDaemons/ :
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple Computer//DTD PLIST 1.0//EN"
"http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>Label</key>
<string>ma.crontab.cpu_load</string>
<key>UserName</key>
<string>patpro</string>
<key>ProgramArguments</key>
<array>
<string>/Users/patpro/bin/cpu_load.sh</string>
</array>
<key>StartInterval</key>
<integer>60</integer>
</dict>
</plist>
Le champs Label doit être unique, on reprend en général le nom du fichier, ici ma.crontab.cpu_load.plist, en omettant le suffix .plist.
Le Username correspond au login de l'utilisateur sous le quel sera lancée la commande.
ProgramArguments est un tableau qui peut contenir plusieurs arguments. Le premier argument (string) est toujours le nom de la commande à exécuter. Les strings suivants (facultatifs) sont les arguments que l'on souhaite passer à la commande.
Pour finir, StartInterval est le nombre de secondes qui sépare chaque lancement de la commande. Il ne peut pas être inférieur à 60, car launchd ne scrute sa liste de lancement que toutes les 60 secondes. Pour la gestion de la périodicité de date (tous les jours à 3h, ou le dimanche à 12h...) on utilise à la place de StartInterval le mot clé StartCalendarInterval (voir le man de launchd.plist pour la syntaxe).
De la même manière, la seconde ligne de ma crontab se traduirait par un fichier ma.crontab.cpu_load_graphs.plist au contenu suivant :
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple Computer//DTD PLIST 1.0//EN"
"http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>Label</key>
<string>ma.crontab.cpu_load_graphs</string>
<key>UserName</key>
<string>patpro</string>
<key>ProgramArguments</key>
<array>
<string>/Users/patpro/bin/cpu_load_graphs.sh</string>
</array>
<key>StartInterval</key>
<integer>900</integer>
</dict>
</plist>
Il est possible d'ajouter une directive à ces fichiers plist si on souhaite logger les erreurs d'exécution :
<key>StandardErrorPath</key>
<string>/tmp/sortie-err.log</string>
Une fois que l'on a créé tous les fichiers adéquats dans /Library/LaunchDaemons/, on peut activer les plists launchd (sans oublier de neutraliser les crontabs) :
sudo launchctl load /Library/LaunchDaemons/ma.crontab.cpu_load*
Il peut arriver que certaines crontabs soient trop complexes pour launchd. Par exemple, je pense que launchd ne sait pas gérer une périodicité de lancement d'une fois toutes les 15 minutes du lundi au vendredi. J'avoue néanmoins que je n'ai pas vérifié ;)
edit : launchd peut gérer cela, mais ce n'est pas élégant, voir l'épisode 2.
 Quand on ajoute une carte wifi dans un boîtier d'ordinateur, on est souvent limité à deux modes d'utilisation. Le mode "infrastructure" permet de lier la carte wifi de l'ordinateur à une borne wifi (access point). Le mode ad-hoc permet quant à lui de créer un réseau poste à poste entre deux machines, sans passer par une borne intermédiaire.
Quand on ajoute une carte wifi dans un boîtier d'ordinateur, on est souvent limité à deux modes d'utilisation. Le mode "infrastructure" permet de lier la carte wifi de l'ordinateur à une borne wifi (access point). Le mode ad-hoc permet quant à lui de créer un réseau poste à poste entre deux machines, sans passer par une borne intermédiaire. Comme disait
Comme disait 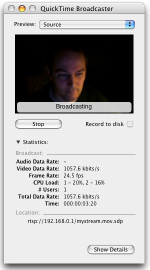 Une fois les réglages effectués, la diffusion est lancée en cliquant sur "Broadcast" dans la partie gauche de la fenêtre ("record to disk" doit être décoché). Les données de cette fenêtre sont alors mises à jour, et l'URL du flux vidéo est donnée. Elle suit normalement ce schéma : rtsp://adresse-dss/mystream.mov.sdp. C'est cette URL que vous devez distribuer à vos admirateurs pour qu'ils la collent dans leur QuickTime (ou dans leur navigateur, si ce dernier sait que les URL rtsp sont à renvoyer à QuickTime). Bien sûr, si la machine qui héberge le DSS a plusieurs adresses IP, elles sont toutes utilisables. Il faut cependant penser à ouvrir le firewall de celle-ci pour autoriser les connexions entrantes sur le port 554.
Une fois les réglages effectués, la diffusion est lancée en cliquant sur "Broadcast" dans la partie gauche de la fenêtre ("record to disk" doit être décoché). Les données de cette fenêtre sont alors mises à jour, et l'URL du flux vidéo est donnée. Elle suit normalement ce schéma : rtsp://adresse-dss/mystream.mov.sdp. C'est cette URL que vous devez distribuer à vos admirateurs pour qu'ils la collent dans leur QuickTime (ou dans leur navigateur, si ce dernier sait que les URL rtsp sont à renvoyer à QuickTime). Bien sûr, si la machine qui héberge le DSS a plusieurs adresses IP, elles sont toutes utilisables. Il faut cependant penser à ouvrir le firewall de celle-ci pour autoriser les connexions entrantes sur le port 554.