[This is the English translation by DeepL]
[Version originale en français]
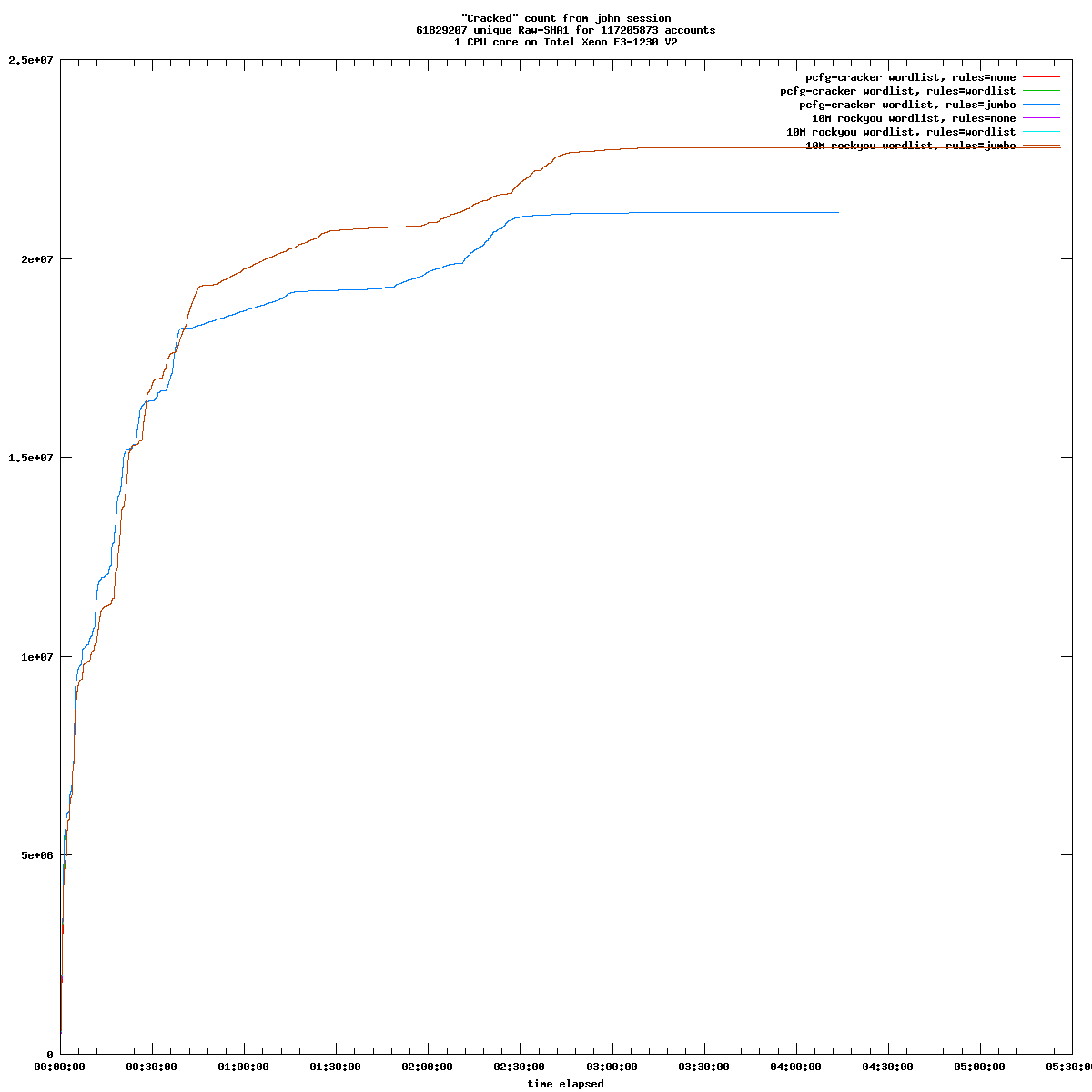
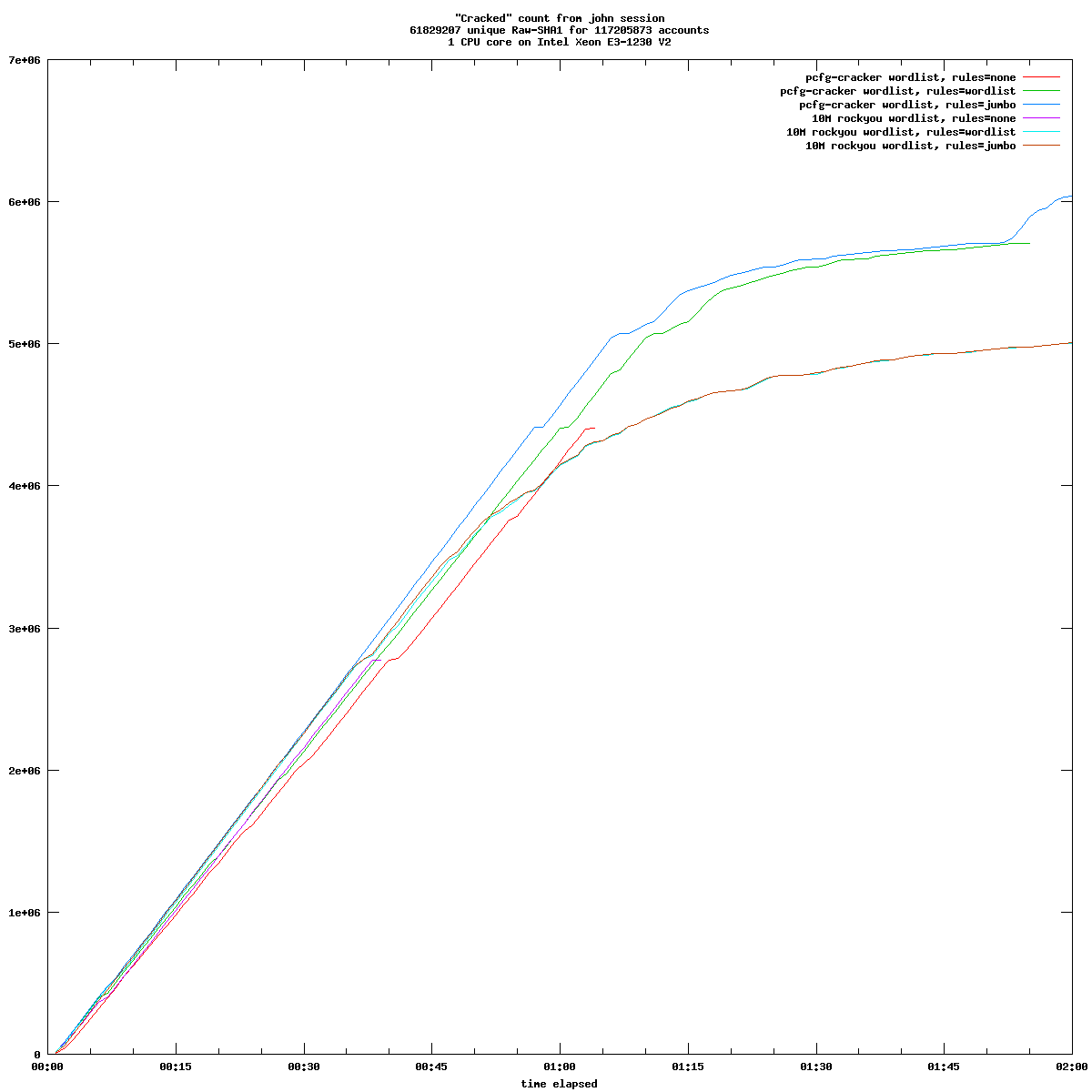
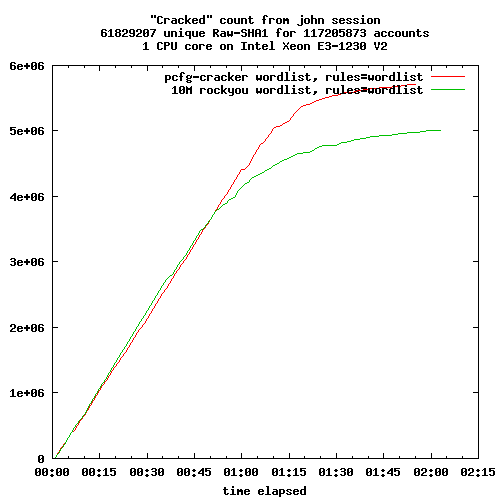
The functional scope of the three backup solutions is relatively equivalent. Each operates in "push" mode, i.e. the client initiates the backup to the server. This mode of operation is undoubtedly best suited to people who manage a small handful of machines. The "pull" mode is available for Borg, but requires a few adjustments.
All three programs use duplication and compression mechanisms to limit the volume of data transmitted and stored. With Kopia, compression is not activated by default. All three also implement backup retention and expiration management, repository maintenance mechanisms, etc.
Borgbackup
 Borgbackup, or Borg, is a solution developed in Python. It is relatively easy to install, but does not allow Windows workstations to be backed up. Its documentation is relatively exhaustive, and its ecosystem includes automation and GUI solutions. It evolves regularly. Tests were carried out with version 1.2.7. Branch 1.4 (beta) is available and branch 2 is under active development.
Borgbackup, or Borg, is a solution developed in Python. It is relatively easy to install, but does not allow Windows workstations to be backed up. Its documentation is relatively exhaustive, and its ecosystem includes automation and GUI solutions. It evolves regularly. Tests were carried out with version 1.2.7. Branch 1.4 (beta) is available and branch 2 is under active development.
To use Borg, the software must also be installed on the destination server. This is a constraint that may prevent some people from using Borg. Remote backup requires an SSH connection. In addition, access to the backup repository is exclusive (lock), i.e. it is not possible to back up several machines to the same repository at the same time. Furthermore, backing up multiple clients to the same repository is discouraged for various reasons.
Should the client machine be compromised, there is cause for concern that the backup software present on the machine will allow remote archives to be destroyed. By default, this is the case. Nonetheless, Borg's client-server operation allows you to add controls. It is possible, for example, to configure the client so that it can only add and restore files, but not delete archives.
All Borg settings are made using command-line arguments. There are no parameter files, although dedicated files can be used to deport lists of exclusions and inclusions, for example.
Official website: https://www.borgbackup.org/
Official documentation: https://borgbackup.readthedocs.io/en/stable/
Cooperative development platform: https://github.com/borgbackup/borg
Kopia
 Kopia is a solution coded in GO. The version used here is 0.15.0 and the project is active. It is a monolithic binary available for different architectures and operating systems. Kopia is Windows-compatible and offers a GUI version. It also works with many different types of remote storage, such as S3, Azure blob Storage, Backblaze B2, WebDAV, SFTP and others. You don't need to install any server-side components to use Kopia.
Kopia is a solution coded in GO. The version used here is 0.15.0 and the project is active. It is a monolithic binary available for different architectures and operating systems. Kopia is Windows-compatible and offers a GUI version. It also works with many different types of remote storage, such as S3, Azure blob Storage, Backblaze B2, WebDAV, SFTP and others. You don't need to install any server-side components to use Kopia.
It is also possible to back up several clients in the same repository. Deduplication can then be achieved across backups of all clients.
Kopia also features an optional "server" mode, which can be configured to add user management when users share the same repository, for example. This feature can also be used to limit the client's rights over stored archives, for example, by prohibiting their deletion. If you don't use the server part of Kopia, you won't be able to prevent a compromised client from deleting its backups.
Kopia lets you manage backup policies that are saved and then applied to backup jobs (or cleanup jobs, since these policies also include the notion of retention). This backup policy management is rather elegant, and allows you to limit the number of command line arguments each time a job is launched.
Official website: https://kopia.io/
Official documentation: https://kopia.io/docs/
Cooperative development platform: https://github.com/kopia/kopia/
Restic
 Restic is also coded in GO. The version used here is 0.16.4 and the project is active. It is available for various architectures and operating systems, including Windows. The range of remote storage solutions supported by Restic is broadly similar to that of Kopia. Restic also offers its own high-performance HTTP server, which implements Restic's REST API. As with Kopia and Borg, this can ensure secure backups by limiting client rights.
Restic is also coded in GO. The version used here is 0.16.4 and the project is active. It is available for various architectures and operating systems, including Windows. The range of remote storage solutions supported by Restic is broadly similar to that of Kopia. Restic also offers its own high-performance HTTP server, which implements Restic's REST API. As with Kopia and Borg, this can ensure secure backups by limiting client rights.
This secure backup protocol, commonly referred to as "append-only", poses constraints on use that can be discouraging for users. Indeed, backing up machines to repositories on which old backups cannot be deleted poses a problem of volume management. For my part, I'd much prefer the client to have full rights over the backups, but for the repository of these backups to be stored on a file system that allows regular snapshots to be generated. In my case, all backups are written to a ZFS file system and automatic snapshots are taken every day with relatively long retention times.
Like Borg, Restic relies exclusively on command-line parameters to configure the various tasks.
Official website: https://restic.net/
Official documentation: https://restic.readthedocs.io/en/stable/index.html
Cooperative development platform: https://github.com/restic/restic
In a nutshell
Everyone has to make up their own mind according to their own needs, but if you don't rule out any scenario (Windows client backup, shared repository or S3 storage...), Borg doesn't have the edge. If, like me, you back up a handful of macOS/FreeBSD/Linux machines to servers on which you can install software and to which you can connect via SSH, then Borg is on a par with Kopia and Restic.
| Borg | Kopia | Restic | |
|---|---|---|---|
| Portability | - | + | + |
| Storage options | - | + | + |
| Transport options | - | + | + |
| Multi-client repository | - | + | + |



 La pandémie de COVID-19 a mis en lumière de nombreux éléments de notre quotidien auxquels nous n'étions pas habitués à prêter attention : l'impact des différents gestes "barrière" sur la transmission, mais aussi le traitement que l'on applique (ou pas) à notre air intérieur.
La pandémie de COVID-19 a mis en lumière de nombreux éléments de notre quotidien auxquels nous n'étions pas habitués à prêter attention : l'impact des différents gestes "barrière" sur la transmission, mais aussi le traitement que l'on applique (ou pas) à notre air intérieur. L'ergonomie se mesure à l'aune des usages de chacun. J'attache pour ma part une grande importance à la qualité des interactions avec les appareils et je n'aime pas la friction dans l'usage quotidien. Pour moi, c'est à nouveau l'Aranet4 qui remporte la palme avec son écran e-ink qui reste lisible tout le temps sans drainer les piles. Une fois paramétré via une application smartphone assez bien faite, plus besoin d'y revenir. C'est agréable.
L'ergonomie se mesure à l'aune des usages de chacun. J'attache pour ma part une grande importance à la qualité des interactions avec les appareils et je n'aime pas la friction dans l'usage quotidien. Pour moi, c'est à nouveau l'Aranet4 qui remporte la palme avec son écran e-ink qui reste lisible tout le temps sans drainer les piles. Une fois paramétré via une application smartphone assez bien faite, plus besoin d'y revenir. C'est agréable.