Le simple mot de passe est de plus en plus souvent pointé du doigt comme ne présentant plus les garanties requises pour l'authentification. L'alliance FIDO montre d'ailleurs l'exemple en assurant le développement et la promotion d'une infrastructure grand public d'authentification double facteur.
Le simple mot de passe est de plus en plus souvent pointé du doigt comme ne présentant plus les garanties requises pour l'authentification. L'alliance FIDO montre d'ailleurs l'exemple en assurant le développement et la promotion d'une infrastructure grand public d'authentification double facteur.
Quels outils pour l'authentification double facteur ?
Il est néanmoins des cas (nombreux) où FIDO et son U2F ne fonctionneront pas pour vous : pour toutes les authentifications qui ne passent pas par un navigateur web.
Pour tout le reste, et en particulier ce qui passe par PAM sur les UNIX et Linux, il existe quelques outils. Google Authenticator fonctionne bien, mais il nécessite que vous utilisiez un client type Google Authenticator, en général sur téléphone malin. Pour quelqu'un qui va s'authentifier rarement, disons 1 à 5 fois par semaine, c'est supportable : initier la connexion, sortir et déverrouiller son téléphone, lancer l'application, recopier le code temporaire (OTP), fermer l'application.
Sur un an je m'authentifie en ssh ou dans sudo environ 4000 fois. C'est à dire en moyenne plus de 11 fois par jour, pour des semaines de 7 jours.
En réalité je travaille toujours un peu moins le week end. Il en résulte qu'une journée de travail peut voir des pics autour de 60 authentifications.
Utiliser une authentification double facteur basée sur une appli mobile ou tout autre appareil affichant un code à recopier serait un échec dans un tel contexte.
C'est là que la Yubikey entre en jeu. Cette petite clé USB programmable est vue comme un clavier par votre ordinateur, et sur pression du doigt elle va taper pour vous l'OTP nécessaire à l'auth double facteur.
Par défaut elle s'appuie sur des serveurs externes pour valider votre OTP. Le jour où pour une raison X ou Y votre réseau n'accède plus à ces serveurs, vous ne pourrez donc plus vous authentifier (il existe malgré tout des contournements). C'est particulièrement problématique si vous tentez justement de reprendre la main sur votre firewall qui a décidé de bloquer l'accès à internet.
Heureusement, Yubico met à disposition de la communauté les outils nécessaires à la création d'un serveur de validation et d'un serveur de stockage des clés, permettant ainsi aux plus exigeants d'entre-nous de monter leur propre infrastructure d'authentification double facteur interne.
Ces outils sont bruts de fonderie, un peu mal dégrossis, et les instructions pour leur mise en place sont parfois approximatives. Le sujet devient encore plus épineux quand on tente de faire l'installation sur FreeBSD. Voici donc quelques instructions basées sur les notes prises lors de mes errances.
Monter des serveurs d'authentification Yubico sur FreeBSD
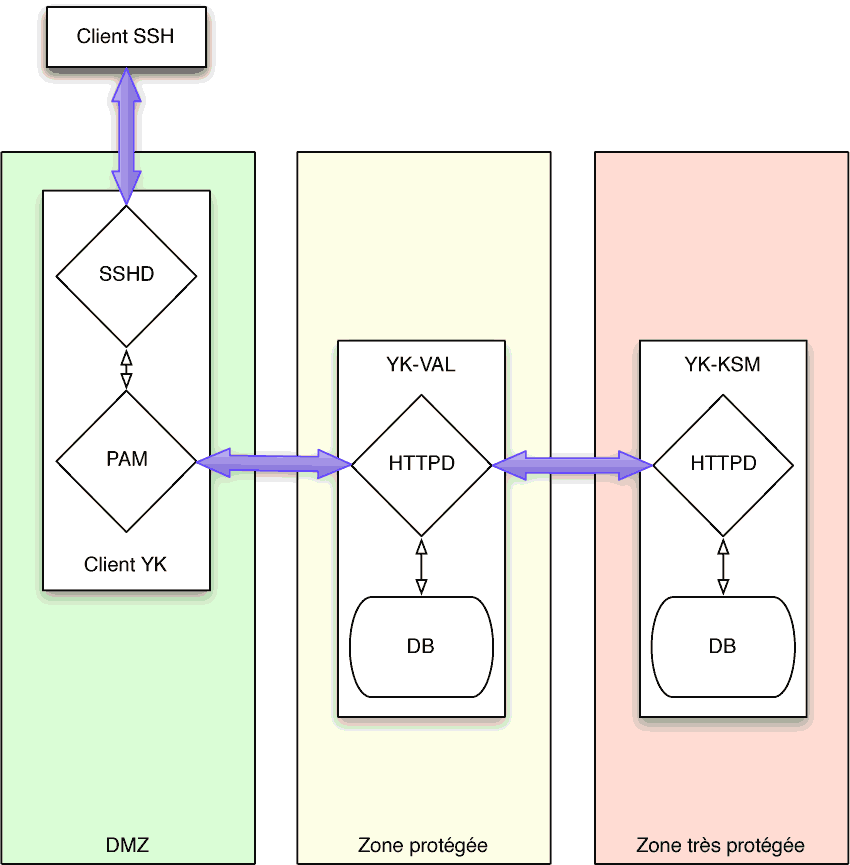
L'infrastructure d'authentification double facteur Yubico est composée de deux services : le service de validation (YK-VAL), c'est à dire celui auquel votre OTP va être envoyé par PAM, et qui donnera la réponse à PAM, et le service de stockage des clés (YK-KSM) sur lequel les clés des utilisateurs sont enregistrées.
Pour des raisons évidentes, il est recommandé de sécuriser au maximum ces deux services. L'idéal est donc de les installer sur deux machines différentes, et d'appliquer de la sécurité en profondeur dessus : firewall en entrée et sortie, si possible un réseau privé entre les deux serveurs, HTTPS partout, etc.
Prérequis : pour aller au bout du process, il vous faudra acheter au moins une clé Yubikey, n'importe laquelle supportant "Yubico OTP".
Pour les besoins de cette maquette, j'ai créé 3 machines virtuelles FreeBSD 10.3. Une d'entre elle sera le serveur de validation ykval.patpro.net, une autre sera le serveur de clé yksm.patpro.net, et la dernière sera un serveur sshd sur lequel je souhaite activer l'authentification double facteur.
Serveur de validation YK-VAL
Sur une installation relativement vierge de FreeBSD 10.3, j'installe les composants suivants :
pkg install apache24 mod_php56 php56-xml php56-curl php56-hash bash sudo mysql57-server php56-pdo_mysql ykclient
Attention, pour une raison que je n'ai plus en tête, l'installation du serveur YK-KSM n'est pas compatible avec mysql57-server. Si vous installez YK-VAL et YK-KSM sur la même machine, choisissez mysql56-server !
Je récupère aussi les sources du serveur de validation Yubico :
fetch https://github.com/Yubico/yubikey-val/archive/master.zip unzip master.zip
Et je tente de suivre les instructions présentées sur la documentation officielle Yubico. Je vous encourage à lire cette documentation en parallèle avec ce blog, car je ne reprends pas ici l'intégralité des explications.
Premier souci, le Makefile n'est pas fonctionnel sur FreeBSD, et j'ai du faire l'installation manuellement. J'ai tenté de scripter les choses un tout petit peu en créant automatiquement les répertoires manquants :
for DIR in $(awk '/prefix = / {print $3}' Makefile); do
[ -d $DIR ] || mkdir -p $DIR
done
Puis en créant une série de variables qu'il faut injecter dans bash :
awk '/prefix = / {print $1"="$3}' Makefile
etcprefix=/etc/yubico/val
sbinprefix=/usr/sbin
phpprefix=/usr/share/yubikey-val
docprefix=/usr/share/doc/yubikey-val
manprefix=/usr/share/man/man1
muninprefix=/usr/share/munin/plugins
wwwprefix=/var/www/wsapi
Ensuite on peut copier les fichiers vers leur destination :
cp ykval-verify.php ${phpprefix}/ykval-verify.php
cp ykval-common.php ${phpprefix}/ykval-common.php
cp ykval-synclib.php ${phpprefix}/ykval-synclib.php
cp ykval-sync.php ${phpprefix}/ykval-sync.php
cp ykval-resync.php ${phpprefix}/ykval-resync.php
cp ykval-db.php ${phpprefix}/ykval-db.php
cp ykval-db-pdo.php ${phpprefix}/ykval-db-pdo.php
cp ykval-db-oci.php ${phpprefix}/ykval-db-oci.php
cp ykval-log.php ${phpprefix}/ykval-log.php
cp ykval-queue ${sbinprefix}/ykval-queue
cp ykval-synchronize ${sbinprefix}/ykval-synchronize
cp ykval-export ${sbinprefix}/ykval-export
cp ykval-import ${sbinprefix}/ykval-import
cp ykval-gen-clients ${sbinprefix}/ykval-gen-clients
cp ykval-export-clients ${sbinprefix}/ykval-export-clients
cp ykval-import-clients ${sbinprefix}/ykval-import-clients
cp ykval-checksum-clients ${sbinprefix}/ykval-checksum-clients
cp ykval-checksum-deactivated ${sbinprefix}/ykval-checksum-deactivated
cp ykval-nagios-queuelength.php ${sbinprefix}/ykval-nagios-queuelength
cp ykval-queue.1 ${manprefix}/ykval-queue.1
cp ykval-synchronize.1 ${manprefix}/ykval-synchronize.1
cp ykval-import.1 ${manprefix}/ykval-import.1
cp ykval-export.1 ${manprefix}/ykval-export.1
cp ykval-gen-clients.1 ${manprefix}/ykval-gen-clients.1
cp ykval-import-clients.1 ${manprefix}/ykval-import-clients.1
cp ykval-export-clients.1 ${manprefix}/ykval-export-clients.1
cp ykval-checksum-clients.1 ${manprefix}/ykval-checksum-clients.1
cp ykval-checksum-deactivated.1 ${manprefix}/ykval-checksum-deactivated.1
cp ykval-munin-ksmlatency.php ${muninprefix}/ykval_ksmlatency
cp ykval-munin-vallatency.php ${muninprefix}/ykval_vallatency
cp ykval-munin-queuelength.php ${muninprefix}/ykval_queuelength
cp ykval-munin-responses.pl ${muninprefix}/ykval_responses
cp ykval-munin-ksmresponses.pl ${muninprefix}/ykval_ksmresponses
cp ykval-munin-yubikeystats.php ${muninprefix}/ykval_yubikeystats
cp ykval-db.sql ${docprefix}/ykval-db.sql
cp ykval-db.oracle.sql ${docprefix}/ykval-db.oracle.sql
À ce stade on a installé différents scripts php dont le shebang est réglé sur un chemin "linux". On pourrait modifier tous les shebangs, mais il est plus simple de créer un lien symbolique de php au bon endroit :
ln -s /usr/local/bin/php /usr/bin/
Ensuite on s'attaque à la configuration de la base de données. J'ai opté pour MySQL, avec lequel je suis plus à l'aise.
Les étapes de la documentation officielle fonctionnent assez bien, mais les droits alloués à l'utilisateur ykval_verifier sont insuffisants. Il faut en effet lui donner les droits d'ajouter des clients dans la table ykval.clients. J'ai donc remplacé la ligne :
GRANT SELECT(id, secret, active) ON ykval.clients TO 'ykval_verifier'@'localhost';
par :
GRANT SELECT,INSERT,UPDATE ON ykval.clients TO 'ykval_verifier'@'localhost';
L'étape 4 de la doc. se résume à ces trois commandes :
mkdir /var/www/wsapi/2.0 ln -sf /usr/share/yubikey-val/ykval-verify.php /var/www/wsapi/2.0/verify.php ln -sf /usr/share/yubikey-val/ykval-sync.php /var/www/wsapi/2.0/sync.php
L'étape 5 consiste à créer l'endroit où seront stockées les préférences de l'application, et à s'assurer qu'elles seront lisibles par Apache.
mkdir /etc/default vi /etc/default/ykval-queue ajouter la ligne : DAEMON_ARGS="/etc/yubico/val:/usr/share/yubikey-val"
vi /var/www/wsapi/2.0/.htaccess ajouter les lignes suivantes : RewriteEngine on RewriteRule ^([^/\.\?]+)(\?.*)?$ $1.php$2 [L] <IfModule mod_php5.c> php_value include_path ".:/etc/yubico/val:/usr/share/yubikey-val" </IfModule>
cd /var/www/wsapi ln -s 2.0/.htaccess /var/www/wsapi/.htaccess
À l'étape 6, il faut récupérer l'exemple de fichier de configuration ykval-config.php fourni avec le code de l'application, et le copier au bon endroit :
cp ykval-config.php /etc/yubico/val/
On édite ce fichier pour renseigner le mot de passe MySQL.
L'étape 7 permet de configurer Apache. Les instructions présentées sont valides pour apache 2.2, mais en version 2.4 il y a quelques modifications à faire. Notamment, autoriser l'accès se fait par la formule Require all granted. Il faut aussi activer le mod_rewrite qui n'est pas actif par défaut sur FreeBSD.
C'est l'occasion de configurer proprement le virtual host, d'activer SSL, etc.
Pour configurer syslogd lors de l'étape 8, il suffit d'ajouter la ligne suivante à /etc/syslog.conf :
local0.* /var/log/ykval.log
et de faire un touch /var/log/ykval.log && service syslogd restart.
La rotation automatique pourra être gérée dans /etc/newsyslog.conf.
J'ai sauté l'étape 9, car je n'ai pas souhaité mettre en place de synchronisation entre différents YK-VAL pour cette maquette. C'est néanmoins une étape à valider si vous souhaitez mettre en place une infrastructure utilisable en production (ie. redondante).
À ce stade vous pourrez passer à l'étape 11. Cette dernière donnera sans doute lieu à de nombreux petits ajustements : config Apache, droits de fichiers, etc. Pas de panique, les logs fournissent normalement pas mal de pistes (notamment /var/log/ykval.log), et vous ne seriez pas ici si vous n'étiez pas capable de vous en sortir.
curl 'http://ykval.patpro.net/wsapi/2.0/verify?id=1&nonce=asdmalksdmlkasmdlkasmdlakmsdaasklmdlak&otp=dteffujehknhfjbrjnlnldnhcujvddbikngjrtgh' h=CqcOcOH1yokoXcDimKDnElyP+f8= t=2016-02-18T17:47:56Z0853 status=NO_SUCH_CLIENT
 La création de nouveaux mots de passe est une activité assez peu passionnante, d'autant que dans certains contextes on peut être amené à répéter l'opération plusieurs fois par jour. Plutôt que d'avoir à réfléchir - et donc de produire un résultat influencé par les travers de l'esprit humain - il est préférable de s'en remettre totalement à la machine.
La création de nouveaux mots de passe est une activité assez peu passionnante, d'autant que dans certains contextes on peut être amené à répéter l'opération plusieurs fois par jour. Plutôt que d'avoir à réfléchir - et donc de produire un résultat influencé par les travers de l'esprit humain - il est préférable de s'en remettre totalement à la machine.