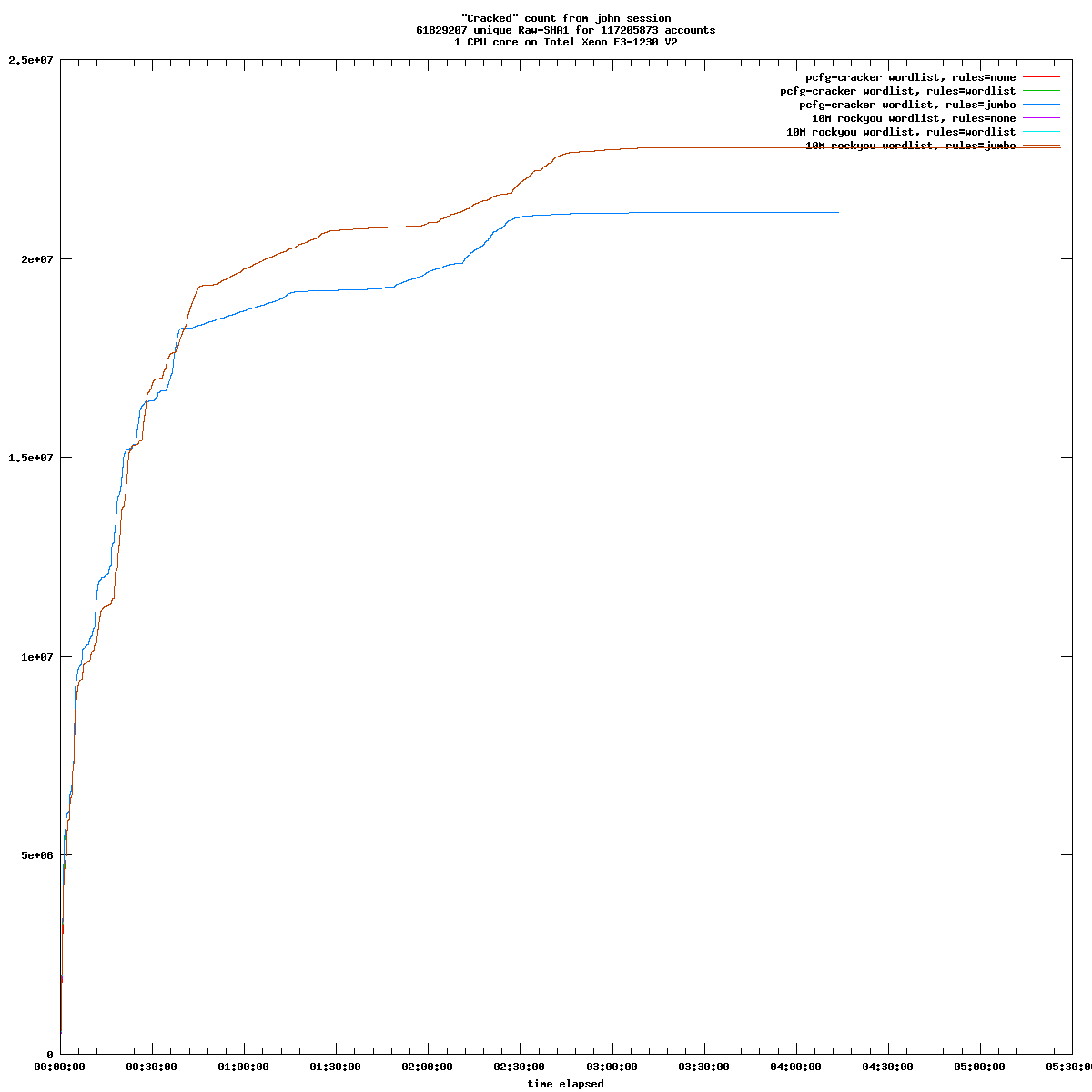
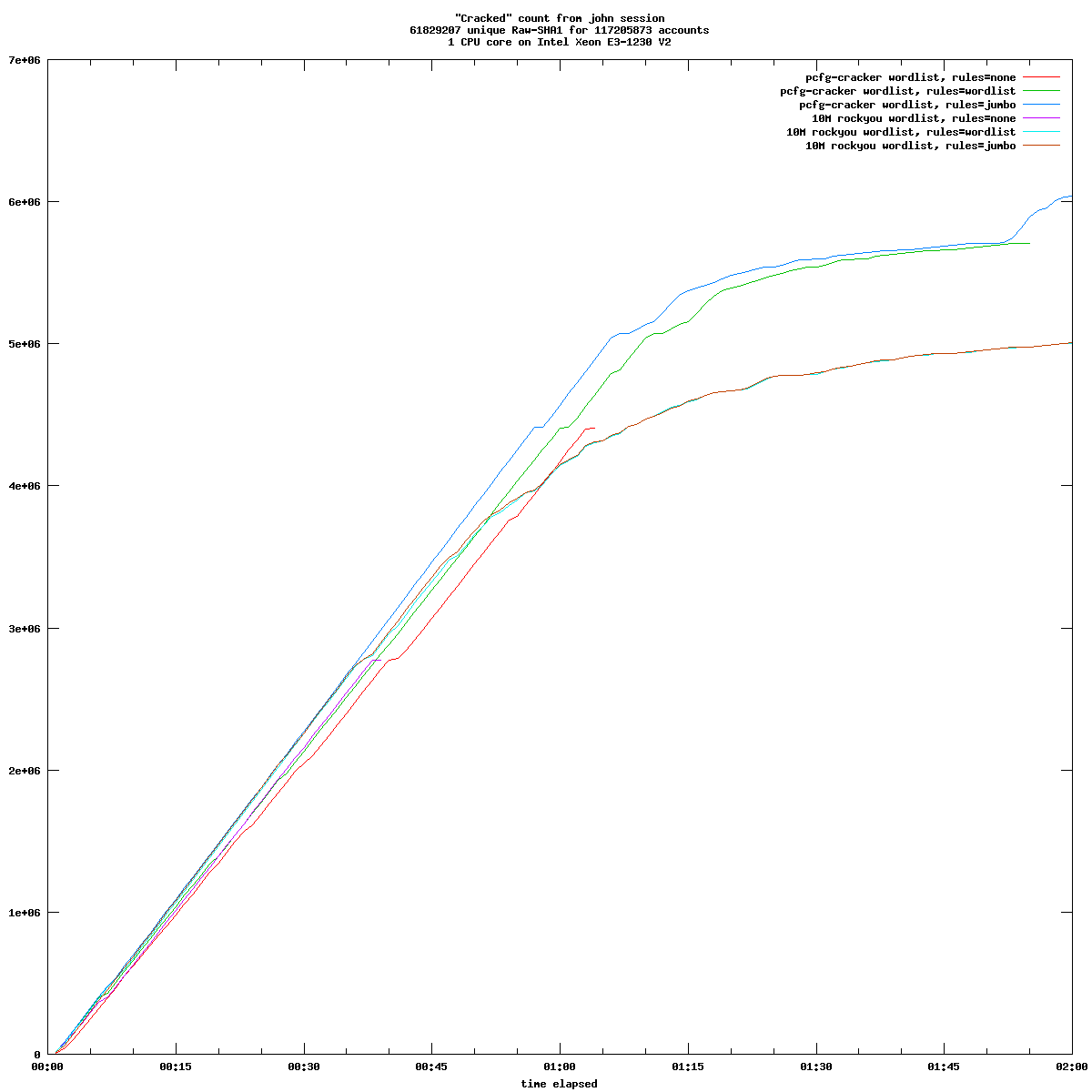
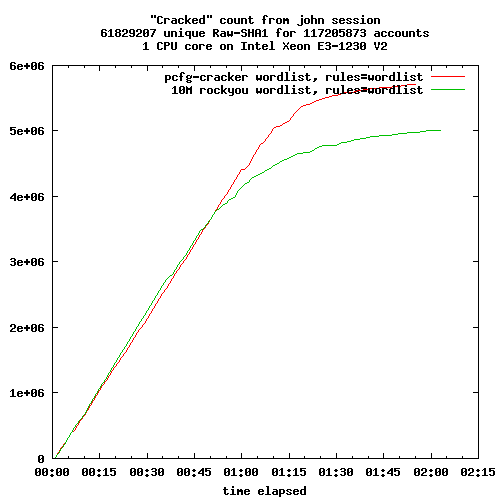
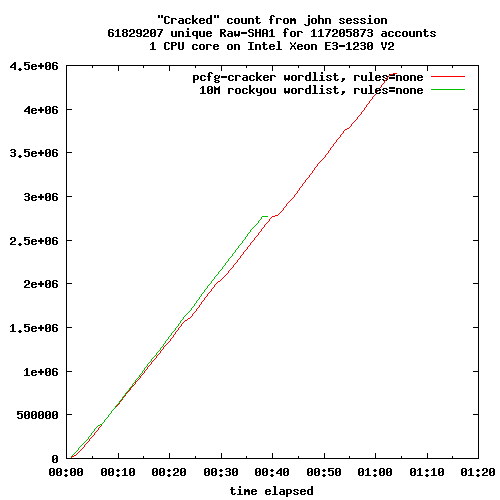
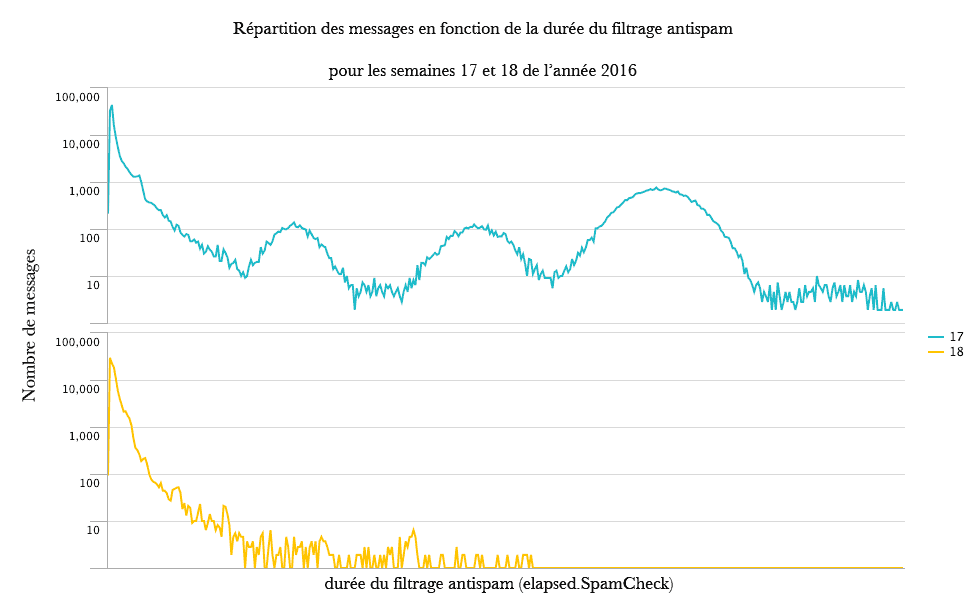
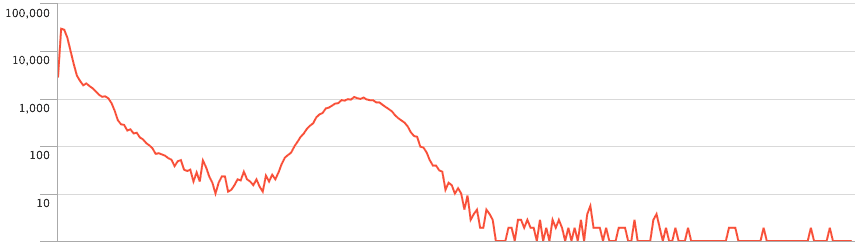
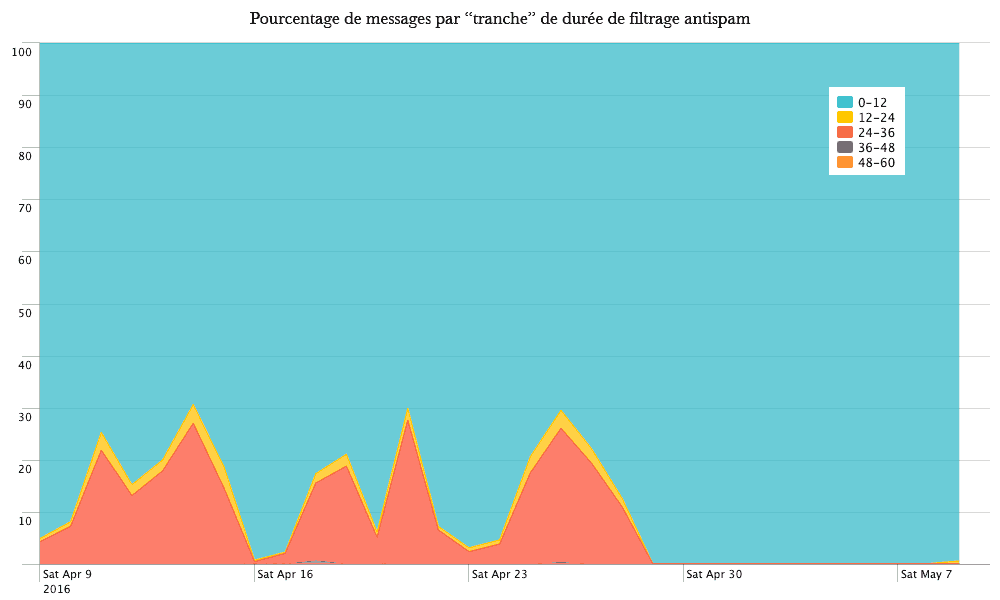
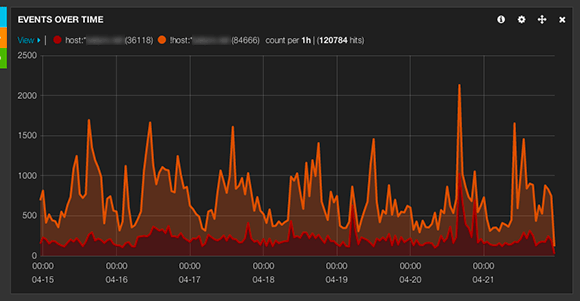
Le périmètre fonctionnel des trois solutions de sauvegarde est relativement équivalent. Chacune fonctionne sur le mode «push», c'est-à-dire que c'est le client qui initie la sauvegarde vers le serveur. Ce mode de fonctionnement est sans doute le plus adapté aux personnes qui gèrent une poignée de machines. Le mode «pull» est disponible pour Borg, mais requiert quelques aménagements.
Les trois programmes utilisent les mécanismes de duplication et de compression pour limiter les volumétries transmises et stockées. Attention cependant, avec Kopia, la compression n'est pas activée par défaut. Ils implémentent aussi tous trois une gestion de la rétention et de l'expiration des sauvegardes, des mécanismes d'entretien du dépôt, etc.
Borgbackup
 Borgbackup, ou Borg pour les intimes, est une solution développée en langage python. Elle s'installe plutôt simplement mais ne permet pas la sauvegarde des postes Windows. Sa documentation est relativement exhaustive et son écosystème inclut des solutions d'automatisation et d'interfaces graphiques. Elle évolue régulièrement. Les tests ont été faits avec la version 1.2.7. La branche 1.4 (beta) est disponible et la branche 2 est en cours de développement actif.
Borgbackup, ou Borg pour les intimes, est une solution développée en langage python. Elle s'installe plutôt simplement mais ne permet pas la sauvegarde des postes Windows. Sa documentation est relativement exhaustive et son écosystème inclut des solutions d'automatisation et d'interfaces graphiques. Elle évolue régulièrement. Les tests ont été faits avec la version 1.2.7. La branche 1.4 (beta) est disponible et la branche 2 est en cours de développement actif.
Pour utiliser Borg, il est nécessaire que le logiciel soit aussi installé sur le serveur de destination. C'est une contrainte qui pourra bloquer certaines personnes. La sauvegarde distante passe par une connexion SSH. De plus, l'accès au dépôt de sauvegarde est exclusif (verrou), c'est-à-dire qu'il n'est pas possible de sauvegarder plusieurs machines dans le même dépôt en même temps. Par ailleurs, la sauvegarde de plusieurs clients sur le même dépôt est découragée pour différentes raisons.
En cas de compromission de la machine cliente, on peut s'inquiéter du fait que le logiciel de sauvegarde présent sur la machine permette la destruction des archives distantes. Par défaut c'est bien le cas. Néanmoins, le fonctionnement client-serveur de Borg permet d'ajouter des contrôles. Il est possible par exemple de configurer le client pour qu'il ne puisse faire que des ajouts et des restaurations de fichiers, mais pas de suppression d'archives.
Tout le paramétrage de Borg se fait avec des arguments en ligne de commande. Il n'y a pas de fichier de paramètres, même si on peut déporter certaines choses dans des fichiers dédiés comme les listes d'exclusions et d’inclusions par exemple.
Site officiel : https://www.borgbackup.org/
Documentation officielle : https://borgbackup.readthedocs.io/en/stable/
Plate-forme de développement coopératif : https://github.com/borgbackup/borg
Kopia
 Kopia est une solution codée en GO. La version utilisée ici est la 0.15.0 et le projet est actif. Il s'agit d'un binaire monolithique disponible pour différentes architectures et systèmes d'exploitation. Kopia est compatible Windows et propose une version graphique. Il fonctionne aussi avec de nombreux stockages distants différents comme par exemple les stockages de type S3, Azure blob Storage, Backblaze B2, WebDAV, SFTP, etc. Il n'est pas nécessaire d'installer des composants côté serveur pour utiliser Kopia.
Kopia est une solution codée en GO. La version utilisée ici est la 0.15.0 et le projet est actif. Il s'agit d'un binaire monolithique disponible pour différentes architectures et systèmes d'exploitation. Kopia est compatible Windows et propose une version graphique. Il fonctionne aussi avec de nombreux stockages distants différents comme par exemple les stockages de type S3, Azure blob Storage, Backblaze B2, WebDAV, SFTP, etc. Il n'est pas nécessaire d'installer des composants côté serveur pour utiliser Kopia.
Il est aussi possible de sauvegarder plusieurs machines dans le même dépôt. La déduplication pourra alors être mise en commun.
Kopia dispose tout de même d'un mode «serveur» facultatif qu'il est possible de configurer pour ajouter une gestion d'utilisateurs, lorsque ces derniers partagent un même dépôt par exemple. C'est aussi grâce à cette fonctionnalité qu'il est possible de limiter les droits du client sur les archives stockées, par exemple en interdisant leur suppression. Si vous n'utilisez pas la partie serveur de Kopia, vous ne pourrez pas empêcher qu’un client compromis supprime ses sauvegardes.
Kopia permet de gérer des politiques de sauvegarde qui sont enregistrés et ensuite applicables à des tâches de sauvegarde (ou de nettoyage, puisque ces politiques incluent aussi la notion de rétention). Cette gestion de politiques de sauvegarde est plutôt élégante et permet de limiter le nombre d'arguments de la ligne de commande à chaque lancement d'une tâche.
Site officiel : https://kopia.io/
Documentation officielle : https://kopia.io/docs/
Plate-forme de développement coopératif : https://github.com/kopia/kopia/
Restic
 Restic est aussi codé en GO. La version utilisée ici est la 0.16.4 et le projet est actif. il est disponible pour différentes architectures et systèmes d'exploitation, y compris Windows. L'éventail de solutions de stockage distant supporté par Restic est à peu près similaire à celui de Kopia. Restic propose en plus son propre serveur HTTP haute performance qui implémente l’API REST de Restic. Cela permet, comme dans le cas de Kopia et de Borg, d'assurer une sécurisation des sauvegardes en limitant les droits du client.
Restic est aussi codé en GO. La version utilisée ici est la 0.16.4 et le projet est actif. il est disponible pour différentes architectures et systèmes d'exploitation, y compris Windows. L'éventail de solutions de stockage distant supporté par Restic est à peu près similaire à celui de Kopia. Restic propose en plus son propre serveur HTTP haute performance qui implémente l’API REST de Restic. Cela permet, comme dans le cas de Kopia et de Borg, d'assurer une sécurisation des sauvegardes en limitant les droits du client.
Ce protocole de sécurisation des sauvegardes, communément appelé «append-only», pose des contraintes d'utilisation qui peuvent être décourageantes pour l'utilisateur. En effet, sauvegarder des machines vers des dépôts sur lesquels on ne peut pas supprimer les anciennes sauvegardes pose un problème de gestion de volumétrie. Pour ma part, je préfère de loin que le client ait tous les droits sur les sauvegardes, mais que le dépôt de ces sauvegardes soit stockés sur un système de fichiers qui permet de générer des snapshots réguliers. Dans mon cas, toutes les sauvegardes sont écrites sur un système de fichiers ZFS et des snapshots automatiques sont pris tous les jours avec des rétentions relativement longues.
Tout comme Borg, Restic s'appuie exclusivement sur des paramètres de ligne de commande pour assurer la configuration des différentes tâches.
Site officiel : https://restic.net/
Documentation officielle : https://restic.readthedocs.io/en/stable/index.html
Plate-forme de développement coopératif : https://github.com/restic/restic
Pour résumer
Chacun doit se faire sa propre idée à l’aune de ses propres besoins, mais si l’on n’exclue aucun scénario (sauvegarde de client Windows, dépôt partagé ou encore stockage S3…), Borg n’a pas l’avantage. Si comme moi vous sauvegardez une poignée de machines macOS/FreeBSD/Linux à destinations de serveurs sur lesquels vous pouvez installer des logiciels et auxquels vous pouvez vous connecter en SSH alors Borg fait jeu égal avec Kopia et Restic.
| Borg | Kopia | Restic | |
|---|---|---|---|
| Portabilité | - | + | + |
| Options de stockage | - | + | + |
| Options de transport | - | + | + |
| Dépôt multi-client | - | + | + |



 La seule piste viable était donc de trouver une solution libre et ouverte, dans un langage que je comprenne a minima, de sorte que je puisse modifier le programme pour l'adapter à un clavier étendu en français.
La seule piste viable était donc de trouver une solution libre et ouverte, dans un langage que je comprenne a minima, de sorte que je puisse modifier le programme pour l'adapter à un clavier étendu en français.



 Après quelques mois d'étude du marché, de documentation sur les technologies, sur les capacités des claviers, sur les marques et leur réputation, de recherche d'un modèle qui réponde à mes besoins et à mes envies (surtout), j'ai fini par jeter mon dévolu sur deux modèles : le ViBE de Vortex Gear (photo ci-dessus), et le Tab 90M aussi chez Vortex Gear.
Après quelques mois d'étude du marché, de documentation sur les technologies, sur les capacités des claviers, sur les marques et leur réputation, de recherche d'un modèle qui réponde à mes besoins et à mes envies (surtout), j'ai fini par jeter mon dévolu sur deux modèles : le ViBE de Vortex Gear (photo ci-dessus), et le Tab 90M aussi chez Vortex Gear. La solution matérielle qui stocke mes frappes clavier en son sein, sans rien faire sortir et qui s'affranchit totalement du système sur lequel est branché le clavier me semble donc la plus sûre à tout point de vue, et la plus adaptée à mes besoins. Bien évidement je me suis assuré que le dongle n'exfiltre aucune données via mes machines. L'exfiltration de données via un réseau hertzien est assez peu probable même si le dispositif semble assez grand pour héberger une SIM et l'électronique nécessaire pour tout renvoyer par SMS. Par ailleurs comme le dongle est branché sur un unique clavier, il m'est toujours possible de saisir des données sensibles via un autre clavier :)
La solution matérielle qui stocke mes frappes clavier en son sein, sans rien faire sortir et qui s'affranchit totalement du système sur lequel est branché le clavier me semble donc la plus sûre à tout point de vue, et la plus adaptée à mes besoins. Bien évidement je me suis assuré que le dongle n'exfiltre aucune données via mes machines. L'exfiltration de données via un réseau hertzien est assez peu probable même si le dispositif semble assez grand pour héberger une SIM et l'électronique nécessaire pour tout renvoyer par SMS. Par ailleurs comme le dongle est branché sur un unique clavier, il m'est toujours possible de saisir des données sensibles via un autre clavier :)