La sécurité des données numériques est au cœur des enjeux actuels, et pas seulement pour les professionnels. Pouvoir chiffrer ses propres données pour les rendre inutilisables pour un voleur éventuel, est donc une nécessité. Sous FreeBSD il est possible de faire du chiffrement sur l'ensemble du disque avec geli(8) ou gbde(4), ou sur un répertoire uniquement avec PEFS. Les deux premières solutions opèrent un chiffrement au niveau bloc. Elles travaillent sur des devices de taille fixe, et ne protègent pas vos données si un pirate accède à la machine quand elle est allumée et que les disques chiffrés sont montés.
PEFS permet de travailler sur un répertoire donc sans avoir à fixer un volume arbitraire au moment de l'initialisation. Le chiffrement se fait au niveau fichier avec une ou plusieurs clés autorisant la hiérarchisation des accès.
Installer PEFS
PEFS est disponible dans les ports et dans les packages. Il est recommandé de faire l'installation par les ports. En effet, l'outil contient un module pour le kernel, et un trop grand écart entre la version de votre noyau et celle qui a servi à la compilation du package peut générer un panic et geler votre système. Aussi, avec un processeur récent vous pourrez activer AES-NI au moment de la compilation du port (accélération matérielle pour le chiffrement AES).
$ cd /usr/ports/sysutils/pefs-kmod
$ sudo make install clean
Pour charger le module automatiquement au redémarrage, ajouter cette ligne dans votre /boot/loader.conf :
pefs_load="YES"
Utiliser PEFS
PEFS s'utilise assez simplement. Il faut commencer par créer un répertoire vide pour stocker les fichiers chiffrés. On peut créer un second répertoire qui servira de point de montage pour la version déchiffrée, mais le montage peut aussi se faire sur le premier répertoire.
$ mkdir ~/coffre.pefs ~/coffre
Ensuite on monte le répertoire (soit vers lui-même, soit comme ici vers un autre pour des raisons de clarté) :
$ sudo pefs mount ~/coffre.pefs ~/coffre
À ce stade, le répertoire ~/coffre est en lecture seule, car nous n'avons pas encore fourni de clé de chiffrement.
$ touch ~/coffre/toto
touch: coffre/toto: Read-only file system
L'ajout d'une clé est une étape simple, mais la documentation officielle manque légèrement d'explications. Il ne s'agit pas ici de fournir une clé une fois pour toute, mais de dire à PEFS de travailler pour la session courante avec cette clé. Si le répertoire est démonté, ou si les clés sont vidangées (flushkeys) il faudra fournir la même clé à nouveau pour accéder aux fichiers.
$ pefs addkey ~/coffre
Enter passphrase: (mot de passe pour (dé)chiffrer vos fichiers)
$ touch ~/coffre/toto
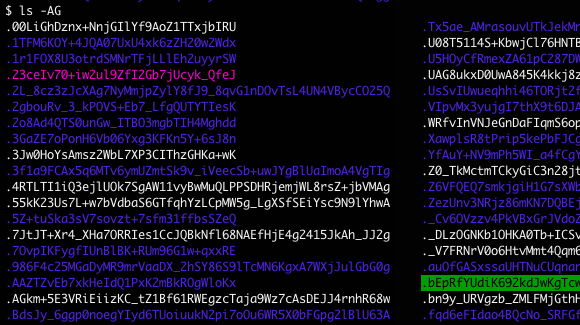
$ ls -A1 ~/coffre*
/home/me/coffre:
toto <- version en clair
/home/me/coffre.pefs:
.SfoQ93cCWWT+NnBB7EYE2ZK402YDSwsT <- version chiffrée
Pour interdire l'accès à vos données vous pouvez simplement utiliser la commande flushkeys, ou aller jusqu'au démontage du répertoire:
$ pefs flushkeys ~/coffre
$ ls -A1 ~/coffre*
/home/me/coffre:
.SfoQ93cCWWT+NnBB7EYE2ZK402YDSwsT <- version chiffrée
/home/me/coffre.pefs:
.SfoQ93cCWWT+NnBB7EYE2ZK402YDSwsT <- version chiffrée
$ sudo pefs unmount ~/coffre
$ ls -A1 ~/coffre*
/home/me/coffre:
(vide)
/home/me/coffre.pefs:
.SfoQ93cCWWT+NnBB7EYE2ZK402YDSwsT <- version chiffrée
Le démontage est facultatif, mais si vous utilisez PEFS dans des scripts, c'est sans doute plus propre. Aussi, faites bien attention, il est possible de monter plusieurs fois le même répertoire au même endroit ce qui peut déboucher sur des situations tout à fait inconfortables. En cas d'utilisation automatisée mettez les bouchées doubles sur les contrôles avant et après chaque commande.
Après le flushkeys, les données sont présentées uniquement dans leur forme chiffrée, mais vous y avez toujours accès ce qui vous permet par exemple de les exporter vers un cloud de sauvegarde (Amazon Glacier, par exemple) en toute sérénité.
Pour déchiffrer vos données, et en admettant que le répertoire soit déjà monté, il vous suffit de reproduire l'étape addkey avec la même clé :
$ pefs addkey ~/coffre
Enter passphrase:
Si à cette étape vous changez la valeur de la clé (volontairement ou par faute de frappe), la nouvelle clé sera acceptée par PEFS. Cette nouvelle clé ne vous donnera pas accès aux anciennes données bien évidemment. Par contre elle vous permettra de stocker de nouveaux fichiers, qui seront chiffrés grâce à cette nouvelle clé. C'est à la fois dangereux et pratique. Si la faute de frappe est votre ennemi vous pouvez jouer la prudence et utiliser un trousseau de clé. Le trousseau se trouve dans le fichier ~/coffre.pefs/.pefs.db et il stocke la ou les clés "officielles" de votre choix. L'initialisation du trousseau se fait avec la commande addchain :
$ pefs addchain -f -Z ~/coffre.pefs
Ensuite, il vous suffira lorsque vous fournirez votre clé de le faire avec l'option -c pour que votre saisie soit comparée au contenu du trousseau :
$ pefs addkey -c ~/coffre
Cela offre une sécurité intéressante mais impose aussi la contrainte d'avoir un fichier dont il faudra prendre soin (attention aux rsync qui pourraient le supprimer si vous utilisez PEFS pour stocker des sauvegardes dans un répertoire chiffrés).
Il existe d'autres possibilités au logiciel PEFS que je ne détaille pas ici, notamment celle de stocker dans le trousseau .pefs.db des chaînes de clés avec héritage parent-enfant, ou encore le module PAM pam_pefs.so qui permet de fournir le montage et le déchiffrement automatique du ~/ d'un utilisateur au moment où il s'authentifie.
Un peu de lecture
Wiki FreeBSD au sujet de PEFS
Tutoriel PEFS
Audit de sécurité rapide sur PEFS